学习爬虫,其基本的操作便是模拟浏览器向服务器发出请求,那么我们需要从哪个地方做起呢? 请求需要我们自己构造吗? 我们需要关心请求这个数据结构怎么实现吗? 需要了解 HTTP、TCP、IP 层的网络传输通信吗? 需要知道服务器如何响应以及响应的原理吗?
可能你无从下手,不过不用担心,Python 的强大之处就是提供了功能齐全的类库来帮助我们实现这些需求。 最基础的 HTTP 库有 urllib、requests、httpx 等。
拿 urllib 这个库来说,有了它,我们只需要关心请求的链接是什么,需要传递的参数是什么,以及如何设置可选的请求头,而无须深入到底层去了解到底是怎样传输和通信的。 有了 urllib 库,只用两行代码就可以完成一次请求和响应的处理过程,得到网页内容,是不是感觉方便极了?
接下来,就让我们从最基础的部分开始了解 HTTP 库的使用方法吧。
2.1 urllib 的使用
首先介绍一个 Python 库,叫作 urllib,利用它就可以实现 HTTP 请求的发送,而且不需要关心 HTTP 协议本身甚至更底层的实现, 我们要做的是指定请求的 URL、请求头、请求体等信息。 此外 urllib 还可以把服务器返回的响应转化为 Python 对象,我们通过该对象便可以方便地获取响应的相关信息,如响应状态码、响应头、响应体等。
而在 Python 3 中,urllib2 库已经不存在了,统一为了 urllib。 首先,我们了解一下 urllib 库的使用方法,它是 Python 内置的 HTTP 请求库,也就是说不需要额外安装,可直接使用。 urllib 库包含如下 4 个模块。
request:这是最基本的 HTTP 请求模块,可以模拟请求的发送。就像在浏览器里输入网址然后按下回车一样,只需要给库方法传入 URL 以及额外的参数,就可以模拟实现发送请求的过程了。
error:异常处理模块。如果出现请求异常,那么我们可以捕获这些异常,然后进行重试或其他操作以保证程序运行不会意外终止。
parse:一个工具模块。提供了许多 URL 的处理方法,例如拆分、解析、合并等。
robotparser:主要用来识别网站的 robots.txt 文件,然后判断哪些网站可以爬,哪些网站不可以,它其实用得比较少。
1. 发送请求
使用 urllib 库的 request 模块,可以方便地发送请求并得到响应。我们先来看下它的具体用法。
urlopen
urllib.request 模块提供了最基本的构造 HTTP 请求的方法,利用这个模块可以模拟浏览器的请求发起过程,同时它还具有处理授权验证(Authentication)、重定向(Redirection)、浏览器 Cookie 以及其他一些功能。
下面我们体会一下 request 模块的强大之处。这里以 Python 官网为例,我们把这个网页抓取下来:
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(response.read().decode('utf-8'))运行结果如图 2-1 所示。
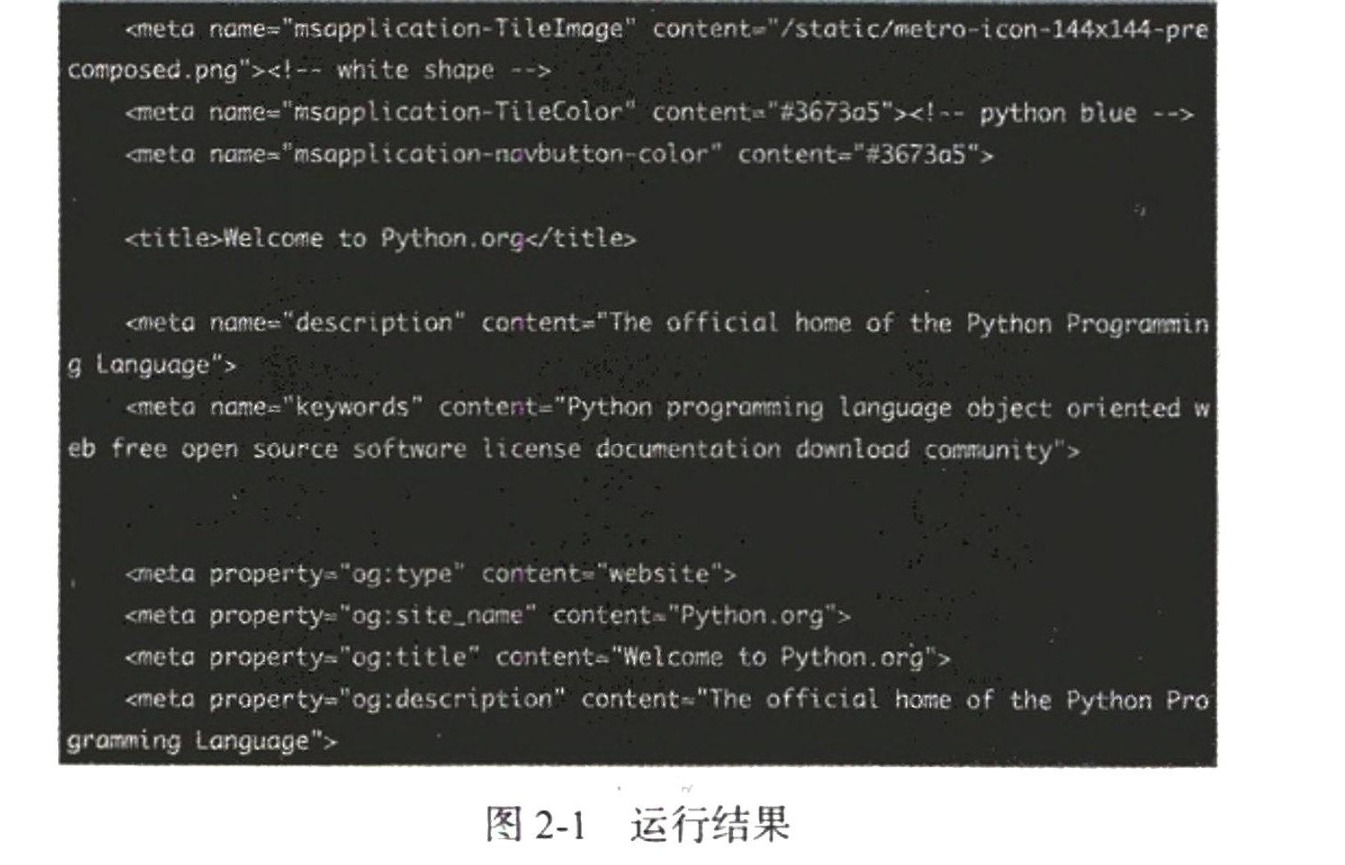
这里我们只用了两行代码,便完成了 Python 官网的抓取,输出了其网页的源代码。 得到源代码之后,我们想要的链接、图片地址、文本信息不就都可以提取出来了吗?
接下来,看看返回的响应到底是什么。利用 type 方法输出响应的类型:
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(type(response))输出结果如下:
<class 'http.client.HTTPResponse'>可以看出,响应是一个 HTTPResponse 类型的对象,主要包含 read、readinto、getheader、getheaders、fileno 等方法,以及 msg、version、status、reason、debuglevel、closed 等属性。
得到响应之后,我们把它赋值给 response 变量,然后就可以调用上述那些方法和属性,得到返回结果的一系列信息了。
例如,调用 read 方法可以得到响应的网页内容、调用 status 属性可以得到响应结果的状态码(200 代表请求成功,404 代表网页未找到等)。
下面再通过一个实例来看看:
import urllib.requestresponse = urllib.request.urlopen('https://www.python.org')
print(response.status)
print(response.getheaders())
print(response.getheader('Server'))运行结果如下:
[('Server', 'nginx'), ('Content-Type', 'text/html; charset=utf-8'), ('X-Frame-Options', 'DENY'), ('Via', '1.1
vegur'), ('Via', '1.1 varnish'), ('Content-Length', '48775'), ('Accept-Ranges', 'bytes'), ('Date', 'Sun, 15
Mar 2020 13:29:01 GMT'), ('Via', '1.1 varnish'), ('Age', '708'), ('Connection', 'close'), ('X-Served-By',
'cache-bwi5120-BWI, cache-tyo19943-TYO'), ('X-Cache', 'HIT, HIT'), ('X-Cache-Hits', '2, 518'), ('X-Timer',
'S1584278942.717942, VSO, VEo'), ('Vary', 'Cookie'), ('Strict-Transport-Security', 'max-age=63072000;
includeSubDomains')]
nginx其中前两个输出分别是响应的状态码和响应的头信息;最后一个输出是调用 getheader 方法,并传入
参数 Server,获取了响应头中 Server 的值,结果是 nginx,意思为服务器是用 Nginx 搭建的。
利用最基本的 urlopen 方法,已经可以完成对简单网页的 GET 请求抓取。
如果想给链接传递一些参数,又该怎么实现呢?首先看一下 urlopen 方法的 API:
`urllib.request.urlopen(url, data=None, [timeout,)*, cafile=None, capath=None, cadefault=False, context=None)`可以发现,除了第一个参数用于传递 URL 之外,我们还可以传递其他内容,例如 data (附加数据)、timeout (超时时间)等。
接下来就详细说明一下 urlopen 方法中几个参数的用法。
data 参数
data 参数是可选的。在添加该参数时,需要使用 bytes 方法将参数转化为字节流编码格式的内容,
即 bytes 类型。另外,如果传递了这个参数,那么它的请求方式就不再是 GET,而是 POST 了。
下面用实例来看一下:
import urllib.parse
import urllib.request
data = bytes(urllib.parse.urlencode({'name': 'germey'}), encoding='utf-8')
response = urllib.request.urlopen('https://www.httpbin.org/post', data=data)
print(response.read().decode('utf-8'))这里我们传递了一个参数 name,值是 germey,需要将它转码成 bytes 类型。转码时采用了 bytes 方法,
该方法的第一个参数得是 str (字符串)类型,因此用 urllib.parse 模块里的 urlencode 方法将字典
参数转化为字符串;第二个参数用于指定编码格式,这里指定为 utf-8。
此处我们请求的站点是 www.httpbin.org,它可以提供 HTTP 请求测试。本次我们请求的 URL 为
https://www.httpbin.org/post,这个链接可以用来测试 POST 请求,能够输出请求的一些信息,其中就
包含我们传递的 data 参数。
上面实例的运行结果如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "germey"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "11",
}可以发现我们传递的参数出现在了 form 字段中,这表明是模拟表单提交,以 POST 方式传输数据。
timeout 参数
timeout 参数用于设置超时时间,单位为秒,意思是如果请求超出了设置的这个时间,还没有得到响应,就会抛出异常。
如果不指定该参数,则会使用全局默认时间。
这个参数支持 HTTP、HTTPS、FTP 请求。
下面用实例来看一下:
import urllib.request
response = urllib.request.urlopen('https://www.httpbin.org/get', timeout=0.1)
print(response.read())运行结果可能如下:
During handling of the above exception, another exception occurred:
Traceback (most recent call last): File "/var/py/python/urllibtest.py", line 4, in <module>
response =urllib.request.urlopen('https://www.httpbin.org/get', timeout=0.1)
urllib.error.URLError: <urlopen error _ssl.c:1059: The handshake operation timed out>这里我们设置超时时间为0.1秒。
程序运行了0.1秒后,服务器依然没有响应,于是抛出了 URLError 异常。
该异常属于 urllib.error 模块,错误原因是超时。
因此可以通过设置这个超时时间,实现当一个网页长时间未响应时,就跳过对它的抓取。此外,利用 try except 语句也可以实现,相关代码如下:
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('https://www.httpbin.org/get', timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout):
print('TIME OUT')这里我们请求了 https://www.httpbin.org/get 这个测试链接,设置超时时间为0.1秒,然后捕获到 URLError 这个异常,并判断异常类型是 socket.timeout,意思是超时异常,因此得出确实是因为超时而报错的结论,最后打印输出了 TIME OUT。
运行结果如下:
TIME OUT按照常理来说,0.1秒几乎不可能得到服务器响应,因此输出了 TIME OUT 的提示。
通过设置 timeout 参数实现超时处理,有时还是很有用的。
其他参数
除了 data 参数和 timeout 参数, urlopen 方法还有 context 参数,该参数必须是 ssl.SSLContext 类型,用来指定 SSL 的设置。
此外,cafile 和 capath 这两个参数分别用来指定 CA 证书和其路径,这两个在请求 HTTPS 链接时会有用。
cadefault 参数现在已经弃用了,其默认值为 False。
至此,我们讲解了 urlopen 方法的用法,通过这个最基本的方法,就可以完成简单的请求和网页抓取。
Request
利用 urlopen 方法可以发起最基本的请求,但它那几个简单的参数并不足以构建一个完整的请求。 如果需要往请求中加入 Headers 等信息,就得利用更强大的 Request 类来构建请求了。
首先,我们用实例感受一下 Request 类的用法:
import urllib.request
request = urllib.request.Request('https://python.org')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))可以发现,我们依然是用 urlopen 方法来发送请求,只不过这次该方法的参数不再是 URL,而是 一个 Request 类型的对象。通过构造这个数据结构,一方面可以将请求独立成一个对象,另一方面可 更加丰富和灵活地配置参数。 下面我们看一下可以通过怎样的参数来构造 Request 类,构造方法如下:
class urllib.request.Request(url, data=None, headers={},
origin_req_host=None, unverifiable=False, method=None)第一个参数 url 用于请求 URL,这是必传参数,其他的都是可选参数。
第二个参数 data 如果要传数据,必须传 bytes 类型的。如果数据是字典,可以先用 urllib.parse 模块里的 urlencode 方法进行编码。
第三个参数 headers 是一个字典,这就是请求头,我们在构造请求时,既可以通过 headers 参数 直接构造此项,也可以通过调用请求实例的 add_header 方法添加。
添加请求头最常见的方法就是通过修改 User-Agent 来伪装浏览器。默认的 User-Agent 是 Python-urllib,我们可以通过修改这个值来伪装浏览器。例如要伪装火狐浏览器,就可以把 User-Agent 设置为:
Mozilla/5.0 (X11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11
第四个参数 origin_req_host 指的是请求方的 host 名称或者 IP 地址。
第五个参数 unverifiable 表示请求是否是无法验证的,默认取值是 False,意思是用户没有足够 的权限来接收这个请求的结果。例如,请求一个 HTML 文档中的图片,但是没有自动抓取图像的权限, 这时 unverifiable 的值就是 True。
第六个参数 method 是一个字符串,用来指示请求使用的方法,例如 GET、POST 和 PUT 等。
下面我们传入多个参数尝试构建 Request 类:
from urllib import request, parse
url = 'https://www.httpbin.org/post'
headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)','Host': 'www.httpbin.org'
}
dict = {'name': 'germey'}
data = bytes (parse.urlencode(dict), encoding='utf-8')
req = request.Request(url=url, data=data, headers=headers, method='POST')
response = request.urlopen(req)
print(response.read().decode('utf-8'))这里我们通过4个参数构造了一个Request类,其中的url即请求 URL, headers 中指定了User-Agent 和 Host, data 用 urlencode 方法和 bytes 方法把字典数据转成字节流格式。 另外,指定了请求方式为POST。
运行结果如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "germey"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "www.httpbin.org",
"User-Agent": "Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)",
"X-Amzn-Trace-Id": "Root=1-5ed27f77-884f503a2aa6760df7679f05"
},
"json": null,
"origin": "17.220.233.154",
"url": "https://www.httpbin.org/post"
}观察结果可以发现,我们成功设置了data、headers 和 method。 通过 add_header 方法添加 headers 的方式如下:
req = request.Request(url=url, data=data, method='POST')
req.add_header('User-Agent', 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)')有了 Request 类,我们就可以更加方便地构建请求,并实现请求的发送啦。
高级用法
我们已经可以构建请求了,那么对于一些更高级的操作(例如Cookie 处理、代理设置等),又该怎么实现呢?
此时需要更强大的工具,于是 Handler 登场了。 简而言之,Handler可以理解为各种处理器,有专门处理登录验证的、处理Cookie的、处理代理设置的。 利用这些Handler,我们几乎可以实现 HTTP 请求中所有的功能。
首先介绍一下 urllib.request 模块里的 BaseHandler类,这是其他所有Handler 类的父类。 它提供了最基本的方法,例如default_open、protocol_request等。 会有各种 Handler 子类继承 BaseHandler类,接下来举几个子类的例子如下。
HTTPDefaultErrorHandler 用于处理HTTP响应错误,所有错误都会抛出HTTPError 类型的异常。
HTTPRedirectHandler 用于处理重定向。
HTTPCookieProcessor 用于处理 Cookie。
ProxyHandler 用于设置代理,代理默认为空。
HTTPPasswordMgr用于管理密码,它维护着用户名密码的对照表。
HTTPBasicAuthHandler 用于管理认证,如果一个链接在打开时需要认证,那么可以用这个类来解决认证问题。
关于这些类如何使用,现在先不急着了解,后面会用实例演示。
另一个比较重要的类是 OpenerDirector,我们可以称之为 Opener。 我们之前用过的 urlopen 方法,实际上就是 urllib 库为我们提供的一个 Opener。
那么,为什么要引入 Opener 呢?因为需要实现更高级的功能。 之前使用的 Request 类和 urlopen 类相当于类库已经封装好的极其常用的请求方法,利用这两个类可以完成基本的请求, 但是现在我们需要实现更高级的功能,就需要深入一层进行配置,使用更底层的实例来完成操作,所以这里就用到了 Opener。
Opener 类可以提供 open 方法,该方法返回的响应类型和 urlopen 方法如出一辙。 那么,Opener 类和 Handler 类有什么关系呢?简而言之就是,利用 Handler 类来构建 Opener 类。
下面用几个实例来看看 Handler 类和 Opener 类的用法。
验证
在访问某些网站时,例如 https://ssr3.scrape.center,可能会弹出这样的认证窗口,如图 2-2 所示。

遇到这种情况,就表示这个网站启用了基本身份认证,英文叫作 HTTP Basic Access Authentication,这是一种登录验证方式,允许网页浏览器或其他客户端程序在请求网站时提供用户名和口令形式的身份凭证。
那么爬虫如何请求这样的页面呢?借助 HTTPBasicAuthHandler 模块就可以完成,相关代码如下:
from urllib.request import HTTPPasswordMgrWithDefaultRealm, HTTPBasicAuthHandler, build_opener
from urllib.error import URLError
username = 'admin'
password = 'admin'
url = 'https://ssr3.scrape.center/'
p = HTTPPasswordMgrWithDefaultRealm()
p.add_password(None, url, username, password)
auth_handler = HTTPBasicAuthHandler(p)
opener = build_opener(auth_handler)
try:
result = opener.open(url)
html = result.read().decode('utf-8')
print(html)
except URLError as e:
print(e.reason)这里首先实例化了一个 HTTPBasicAuthHandler 对象 auth_handler,其参数是 HTTPPasswordMgrWithDefaultRealm 对象,它利用 add_password 方法添加用户名和密码,这样就建立了一个用来处理验证的 Handler 类。
然后将刚建立的 auth_handler 类当作参数传入 build_opener 方法,构建一个 Opener,这个 Opener 在发送请求时就相当于已经验证成功了。
最后利用 Opener 类中的 open 方法打开链接,即可完成验证。这里获取的结果就是验证成功后的页面源码内容。
代理 做爬虫的时候,免不了要使用代理,如果要添加代理,可以这样做:
from urllib.error import URLError
from urllib.request import ProxyHandler, build_opener
proxy_handler = ProxyHandler({
'http': 'http://127.0.0.1:8080',
'https': 'https://127.0.0.1:8080'
})
opener = build_opener(proxy_handler)
try:
response = opener.open('https://www.baidu.com')
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason)这里需要我们事先在本地搭建一个 HTTP 代理,并让其运行在 8080 端口上。
上面使用了 ProxyHandler,其参数是一个字典,键名是协议类型 (例如 HTTP 或者 HTTPS 等)、键值是代理链接,可以添加多个代理。
然后利用这个 Handler 和 build_opener 方法构建了一个 Opener,之后发送请求即可。
Cookie
处理 Cookie 需要用到相关的 Handler。
我们先用实例来看看怎样获取网站的 Cookie,相关代码如下:
import http.cookiejar, urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor (cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('https://www.baidu.com')
for item in cookie:
print(item.name + "=" + item.value)首先,必须声明一个 CookieJar 对象。
然后需要利用 HTTPCookieProcessor 构建一个 Handler,最后利用 build_opener 方法构建 Opener,执行 open 函数即可。
运行结果如下:
BAIDUID=A09E6C4E38753531B9FB4C60CE9FDFCB:FG=1
BIDUPSID=A09E6C4E387535312F8AA46280C6C502
H_PS_PSSID=31358_1452_31325_21088_31110_31253_31605_31271_31463_30823
PSTM-1590854698
BDSVRTM-10
BD HOME=1可以看到,这里分别输出了每个 Cookie 条目的名称和值。
既然能输出,那么可不可以输出文件格式的内容呢?我们知道 Cookie 实际上也是以文本形式保存的。因此答案当然是肯定的,这里通过下面的实例来看看:
import urllib.request, http.cookiejar
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar (filename)
handler = urllib.request.HTTPCookieProcessor (cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('https://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)这时需要将 CookieJar 换成 MozillaCookieJar,它会在生成文件时用到,是 CookieJar 的子类,可以用来处理跟 Cookie 和文件相关的事件,例如读取和保存 Cookie,可以将 Cookie 保存成 Mozilla 型浏览器的 Cookie 格式。
运行上面的实例之后,会发现生成了一个 cookie.txt 文件,该文件内容如下:
Netscape HTTP Cookie File
http://curl.haxx.se/rfc/cookie_spec.html
This is a generated file! Do not edit.
.baidu.com TRUE // FALSE 1622390755 BAIDUID OB4A68D74B0C0E53E5B82AFD9BF9178F:FG=1
.baidu.com TRUE // FALSE 3738338402 BIDUPSID OB4A68D74B0C0E53471FA6329280FA58
.baidu.com TRUE // FALSE 3738338402 PSTM 1590854754
.baidu.com TRUE // FALSE H_PS_PSSID 31262_1438_31325_21127_31110_31596_31673_31464_30823_26350
www.baidu.com FALSE / / FALSE BDSVRTM 0
www.baidu.com FALSE / / FALSE BD_HOME 1另外,LWPCookieJar 同样可以读取和保存 Cookie,只是 Cookie 文件的保存格式和 MozillaCookieJar 不一样,它会保存成 LWP (libwww-perl) 格式。
要保存 LWP 格式的 Cookie 文件,可以在声明时就进行修改:
cookie = http.cookiejar.LWPCookieJar (filename)此时生成的内容如下:
#LWP-Cookies-2.0
Set-Cookie3: BAIDUID="1F30EEDA35C7A94320275F991CA5B3A5:FG=1"; path="/"; domain=".baidu.com"; path_spec;
domain_dot; expires="2021-05-30 16:06:39Z"; comment=bd; version=0
Set-Cookie3: BIDUPSID=1F30EEDA35C7A9433C97CF6245CBC383; path="/"; domain=".baidu.com"; path_spec; domain_dot;
expires="2088-06-17 19:20:46Z"; version=0
Set-Cookie3: H_PS_PSSID=31626_1440_21124_31069_31254_31594_30841_31673_31464_31715_30823; path="/";
domain=".baidu.com"; path_spec; domain_dot; discard; version=0
Set-Cookie3: PSTM=1590854799; path="/"; domain=".baidu.com"; path_spec; domain_dot; expires="2088-06-17
19:20:46Z"; version=0
Set-Cookie3: BDSVRTM=11; path="/"; domain="www.baidu.com"; path_spec; discard; version=0
Set-Cookie3: BD_HOME=1; path="/"; domain="www.baidu.com"; path_spec; discard; version=0由此看来,不同格式的 Cookie 文件差异还是比较大的。
那么,生成 Cookie 文件后,怎样从其中读取内容并加以利用呢?
下面我们以 LWPCookieJar 格式为例来看一下:
import urllib.request, http.cookiejar
cookie = http.cookiejar.LWPCookieJar()
cookie.load('cookie.txt', ignore_discard=True, ignore_expires=True)
handler = urllib.request.HTTPCookieProcessor (cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('https://www.baidu.com')
print(response.read().decode('utf-8'))可以看到,这里调用 load 方法来读取本地的 Cookie 文件,获取了 Cookie 的内容。这样做的前提
我们首先生成了 LWPCookieJar 格式的 Cookie,并保存成了文件。 读取 Cookie 之后,使用同样的方法构建 Handler 类和 Opener 类即可完成操作。
运行结果正常的话,会输出百度网页的源代码。 通过上面的方法,我们就可以设置绝大多数请求的功能。
2. 处理异常
我们已经了解了如何发送请求,但是在网络不好的情况下,如果出现了异常,该怎么办呢? 这时要是不处理这些异常,程序很可能会因为报错而终止运行,所以异常处理还是十分有必要的。
urllib 库中的 error 模块定义了由 request 模块产生的异常。当出现问题时,request 模块便会抛出 error 模块中定义的异常。
URLError
URLError 类来自 urllib 库的 error 模块,继承自 OSError 类,是 error 异常模块的基类,由 request 模块产生的异常都可以通过捕获这个类来处理。
它具有一个属性 reason,即返回错误的原因。 下面用一个实例来看一下:
from urllib import request, error
try:
response = request.urlopen('https://cuiqingcai.com/404')
except error.URLError as e:
print(e.reason)我们打开了一个不存在的页面,照理来说应该会报错,但是我们捕获了 URLError 这个异常,运行结果如下:
Not Found程序没有直接报错,而是输出了错误原因,这样可以避免程序异常终止,同时异常得到了有效处理。
HTTPError
HTTPError 是 URLError 的子类,专门用来处理 HTTP 请求错误,例如认证请求失败等。它有如下 3 个属性。
code:返回 HTTP 状态码,例如 404 表示网页不存在,500 表示服务器内部错误等。
reason:同父类一样,用于返回错误的原因。
headers:返回请求头。
下面我们用几个实例来看看:
from urllib import request, error
try:
response = request.urlopen('https://cuiqingcai.com/404')
except error.HTTPError as e:
print(e.reason, e.code, e.headers, sep='\n')运行结果如下:
Not Found
Server: nginx/1.10.3 (Ubuntu)Date: Sat, 30 May 2020 16:08:42 GMT
Content-Type: text/html; charset=UTF-8
Transfer-Encoding: chunked
Connection: close
Set-Cookie: PHPSESSID=kp1a1b003a0pcf688kt73gc780; path=/
Pragma: no-cache
Vary: Cookie
Expires: Wed, 11 Jan 1984 05:00:00 GMT
Cache-Control: no-cache, must-revalidate, max-age=0
Link: <https://cuiqingcai.com/wp-json/>; rel="https://api.w.org/"依然是打开同样的网址,这里捕获了HTTPError 异常,输出了reason、code 和 headers 属性。 因为URLError 是HTTPError 的父类,所以可以先选择捕获子类的错误,再捕获父类的错误,于是上述代码的更好写法如下:
from urllib import request, error
try:
response = request.urlopen('https://cuiqingcai.com/404')
except error.HTTPError as e:
print(e.reason, e.code, e.headers, sep='\n')
except error.URLError as e:
print(e.reason)
else:
print('Request Successfully')这样就可以做到先捕获 HTTPError,获取它的错误原因、状态码、请求头等信息。 如果不是HTTPError 异常,就会捕获 URLError异常,输出错误原因。 最后,用else语句来处理正常的逻辑。 这是一个较好的异常处理写法。
有时候,reason 属性返回的不一定是字符串,也可能是一个对象。再看下面的实例:
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('https://www.baidu.com', timeout=0.01)
except urllib.error.URLError as e:
print(type(e.reason))
if isinstance(e.reason, socket.timeout):
print('TIME OUT')这里我们直接设置超时时间来强制抛出 timeout 异常。 运行结果如下:
<class'socket.timeout'>
TIME OUT可以发现,reason 属性的结果是 socket.timeout类。所以这里可以用isinstance 方法来判断它的类型,做出更详细的异常判断。 本节我们讲述了 error 模块的相关用法,通过合理地捕获异常可以做出更准确的异常判断,使程序更加稳健。
3. 解析链接
前面说过,urllib 库里还提供了 parse模块,这个模块定义了处理URL的标准接口,例如实现 URL 各部分的抽取、合并以及链接转换。 它支持如下协议的URL处理:file、ftp、gopher、hdl、http、https、imap、mailto、mms、news、nntp、prospero、rsync、rtsp、rtspu、sftp、sip、sips、snews、svn、svn+ssh、telnet 和 wais。
下面我们将介绍 parse 模块中的常用方法,看一下它的便捷之处。
urlparse
该方法可以实现 URL 的识别和分段,这里先用一个实例来看一下:
from urllib.parse import urlparse
result = urlparse('https://www.baidu.com/index.html; user?id=5#comment')
print(type(result))
print(result)这里我们利用 urlparse 方法对一个 URL 进行了解析,然后输出了解析结果的类型以及结果本身。
运行结果如下:
<class 'urllib.parse.ParseResult'>
ParseResult(scheme='https', netloc='www.baidu.com', path='/index.html', params='user', query='id=5',
fragment='comment')可以看到,解析结果是一个 ParseResult 类型的对象,包含6部分,分别是 scheme、netloc、path、params、query 和 fragment。
再观察一下上述实例中的 URL:
https://www.baidu.com/index.html; user?id=5#comment可以发现,urlparse 方法在解析 URL 时有特定的分隔符。 例如://前面的内容就是 scheme,代表协议。 第一个/符号前面便是 netloc,即域名;后面是 path,即访问路径。 分号;后面是 params,代表参数。 问号?后面是查询条件 query,一般用作 GET 类型的 URL。 井号#后面是锚点 fragment,用于直接定位页面内部的下拉位置。
于是可以得出一个标准的链接格式,具体如下:
scheme://netloc/path; params?query#fragment一个标准的 URL 都会符合这个规则,利用 urlparse 方法就可以将它拆分开来。
除了这种最基本的解析方式外,urlparse 方法还有其他配置吗?接下来,看一下它的 API 用法:
urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)可以看到,urlparse 方法有3个参数。
urlstring:这是必填项,即待解析的 URL。
scheme:这是默认的协议(例如 http 或 https 等)。如果待解析的 URL 没有带协议信息,就会将这个作为默认协议。我们用实例来看一下:
from urllib.parse import urlparse
result = urlparse('www.baidu.com/index.html;user?id=5#comment', scheme='https')
print(result)运行结果如下:
ParseResult(scheme='https', netloc='', path='www.baidu.com/index.html',params='user', query='id=5',
fragment='comment')可以发现,这里提供的 URL 不包含最前面的协议信息,但是通过默认的 scheme 参数,返回了结果 https。
假设带上协议信息:
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment', scheme='https')则结果如下:
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=5',
fragment='comment')可见,scheme 参数只有在 URL 中不包含协议信息的时候才生效。如果 URL 中有,就会返回解析出的 scheme。
allow_fragments: 是否忽略 fragment。
如果此项被设置为 False,那么 fragment 部分就会被忽略,它会被解析为 path、params 或者 query 的一部分,而 fragment 部分为空。
下面我们用实例来看一下:
from urllib.parse import urlparse
result = urlparse('https://www.baidu.com/index.html;user?id=5#comment', allow_fragments=False)
print(result)运行结果如下:
ParseResult(scheme='https', netloc='www.baidu.com', path='/index.html', params='user', query='id=5#comment',
fragment='')假设 URL 中不包含 params 和 query,我们再通过实例看一下:
from urllib.parse import urlparse
result = urlparse('https://www.baidu.com/index.html#comment', allow_fragments=False)
print(result)运行结果如下:
ParseResult(scheme='https', netloc='www.baidu.com', path='/index.html#comment', params='', query='',
fragment='')可以发现,此时 fragment 会被解析为 path 的一部分。 返回结果 ParseResult 实际上是一个元组,既可以用属性名获取其内容,也可以用索引来顺序获取。实例如下:
from urllib.parse import urlparse
result = urlparse('https://www.baidu.com/index.html#comment', allow_fragments=False)
print(result.scheme, result[0], result.netloc, result[1], sep='\n')这里我们分别用属性名和索引获取了 scheme 和 netloc,运行结果如下:
https
https
www.baidu.com
www.baidu.com可以发现,两种获取方式都可以成功获取,且结果是一致的。
urlunparse 有了 urlparse 方法,相应就会有它的对立方法 urlunparse,用于构造 URL。 这个方法接收的参数是一个可迭代对象,其长度必须是 6,否则会抛出参数数量不足或者过多的问题。 先用一个实例看一下:
from urllib.parse import urlunparse
data = ['https', 'www.baidu.com', 'index.html', 'user', 'a=6', 'comment']
print(urlunparse(data))这里参数 data 用了列表类型。当然,也可以用其他类型,例如元组或者特定的数据结构。
运行结果如下: https://www.baidu.com/index.html;user?a=6#comment 这样我们就成功实现了URL的构造。
urlsplit
这个方法和 urlparse 方法非常相似,只不过它不再单独解析 params 这一部分(params 会合并到 path 中),只返回 5 个结果。实例如下:
from urllib.parse import urlsplit
result = urlsplit('https://www.baidu.com/index.html;user?id=5#comment')
print(result)运行结果如下:
SplitResult(scheme='https', netloc='www.baidu.com', path='/index.html;user', query='id=5',
fragment='comment')可以发现,返回结果是 SplitResult,这其实也是一个元组,既可以用属性名获取其值,也可以 用索引获取。实例如下:
from urllib.parse import urlsplit
result = urlsplit('https://www.baidu.com/index.html;user?id=5#comment')
print(result.scheme, result[0])运行结果如下:
https httpsurlunsplit
与 urlunparse 方法类似,这也是将链接各个部分组合成完整链接的方法,传入的参数也是一个可 迭代对象,例如列表、元组等,唯一区别是这里参数的长度必须为 5。实例如下:
from urllib.parse import urlunsplit
data = ['https', 'www.baidu.com', 'index.html', 'a=6', 'comment']
print(urlunsplit(data))运行结果如下:
https://www.baidu.com/index.html?a=6#commenturljoin
urlunparse 和 urlunsplit 方法都可以完成链接的合并,不过前提都是必须有特定长度的对象,链 接的每一部分都要清晰分开。 除了这两种方法,还有一种生成链接的方法,是 urljoin。我们可以提供一个 base_url (基础链 接) 作为该方法的第一个参数,将新的链接作为第二个参数。urljoin 方法会分析 base_url 的 scheme、 netloc 和 path 这 3 个内容,并对新链接缺失的部分进行补充,最后返回结果。 下面通过几个实例看一下:
from urllib.parse import urljoin
print(urljoin('https://www.baidu.com', 'FAQ.html'))
print(urljoin('https://www.baidu.com', 'https://cuiqingcai.com/FAQ.html'))
print(urljoin('https://www.baidu.com/about.html', 'https://cuiqingcai.com/FAQ.html'))
print(urljoin('https://www.baidu.com/about.html', 'https://cuiqingcai.com/FAQ.html?question=2'))
print(urljoin('https://www.baidu.com?wd=abc', 'https://cuiqingcai.com/index.php'))
print(urljoin('https://www.baidu.com', '?category=2#comment'))print(urljoin('www.baidu.com', '?category=2#comment'))
print(urljoin('www.baidu.com#comment', '?category=2'))运行结果如下:
https://www.baidu.com/FAQ.html
https://cuiqingcai.com/FAQ.html
https://cuiqingcai.com/FAQ.html
https://cuiqingcai.com/FAQ.html?question=2
https://cuiqingcai.com/index.php
https://www.baidu.com?category=2#comment
www.baidu.com?category=2#comment
www.baidu.com?category=2可以发现,base_url 提供了三项内容:scheme、netloc 和 path。 如果新的链接里不存在这三项,就予以补充;如果存在,就使用新的链接里面的,base_url中的是不起作用的。 通过 urljoin 方法,我们可以轻松实现链接的解析、拼合与生成。
urlencode
这里我们再介绍一个常用的方法————urlencode,它在构造 GET 请求参数的时候非常有用,实例如下:
from urllib.parse import urlencode
params = {
'name': 'germey',
'age': 25
}
base_url = 'https://www.baidu.com?'
url = base_url + urlencode(params)
print(url)这里首先声明了一个字典 params,用于将参数表示出来,然后调用 urlencode 方法将 params 序列化为GET请求的参数。
运行结果如下:
https://www.baidu.com?name=germey&age=25可以看到,参数已经成功地由字典类型转化为GET请求参数。 urlencode 方法非常常用。有时为了更加方便地构造参数,我们会事先用字典将参数表示出来,然后将字典转化为URL的参数时,只需要调用该方法即可。
parse_qs
有了序列化,必然会有反序列化。利用 parse_qs方法,可以将一串GET请求参数转回字典,实例如下:
from urllib.parse import parse_qs
query = 'name=germey&age=25'
print(parse_qs(query))运行结果如下:
{'name': ['germey'], 'age': ['25']}可以看到,URL的参数成功转回为字典类型。
parse_qsl
parse_qsl 方法用于将参数转化为由元组组成的列表,实例如下:
from urllib.parse import parse_qsl
query = 'name=germey&age=25'
print(parse_qsl(query))运行结果如下:
[('name', 'germey'), ('age', '25')]可以看到,运行结果是一个列表,该列表中的每一个元素都是一个元组,元组的第一个内容是参数名,第二个内容是参数值。
quote
该方法可以将内容转化为 URL 编码的格式。 当 URL 中带有中文参数时,有可能导致乱码问题,此时用 quote 方法可以将中文字符转化为 URL 编码,实例如下:
from urllib.parse import quote
keyword = '壁纸'
url = 'https://www.baidu.com/s?wd=' + quote(keyword)
print(url)这里我们声明了一个中文的搜索文字,然后用 quote 方法对其进行 URL 编码,最后得到的结果如下:
https://www.baidu.com/s?wd=%E5%A3%81%E7%BA%B8unquote
有了 quote 方法,当然就有 unquote 方法,它可以进行 URL 解码,实例如下:
from urllib.parse import unquote
url = 'https://www.baidu.com/s?wd=%E5%A3%81%E7%BA%B8'
print(unquote(url))这里的 url 是上面得到的 URL 编码结果,利用 unquote 方法将其还原,结果如下:
https://www.baidu.com/s?wd=壁纸可以看到,利用 unquote 方法可以方便地实现解码。
本节我们介绍了 parse 模块的一些常用 URL 处理方法。有了这些方法,我们可以方便地实现 URL 的解析和构造,建议熟练掌握。
4. 分析 Robots 协议
利用 urllib 库的 robotparser 模块,可以分析网站的 Robots 协议。我们再来简单了解一下这个模块的用法。
Robots 协议
Robots 协议也称作爬虫协议、机器人协议,全名为网络爬虫排除标准 (Robots Exclusion Protocol),用来告诉爬虫和搜索引擎哪些页面可以抓取、哪些不可以。 它通常是一个叫作 robots.txt 的文本文件,一般放在网站的根目录下。
搜索爬虫在访问一个站点时,首先会检查这个站点根目录下是否存在 robots.txt 文件,如果存在,就会根据其中定义的爬取范围来爬取。 如果没有找到这个文件,搜索爬虫便会访问所有可直接访问的页面。
下面我们看一个 robots.txt 的样例:
User-agent: *Disallow: /
Allow: /public/这限定了所有搜索爬虫只能爬取 public 目录。
将上述内容保存成 robots.txt 文件,放在网站的根目录下,和网站的入口文件(例如 index.php、index.html 和 index.jsp 等)放在一起。
上面样例中的 User-agent 描述了搜索爬虫的名称,这里将其设置为 *,代表 Robots 协议对所有爬取爬虫都有效。
例如,我们可以这样设置:
User-agent: Baiduspider这代表设置的规则对百度爬虫是有效的。如果有多条 User-agent 记录,则意味着有多个爬虫会受到爬取限制,但至少需要指定一条。
Disallow 指定了不允许爬虫爬取的目录,上例设置为 /,代表不允许爬取所有页面。
Allow 一般不会单独使用,会和 Disallow 一起用,用来排除某些限制。
上例中我们设置为 /public/,结合 Disallow 的设置,表示所有页面都不允许爬取,但可以爬取 public 目录。
下面再来看几个例子。禁止所有爬虫访问所有目录的代码如下:
User-agent: *
Disallow: /允许所有爬虫访问所有目录的代码如下:
User-agent: *
Disallow:另外,直接把 robots.txt 文件留空也是可以的。
禁止所有爬虫访问网站某些目录的代码如下:
User-agent: *
Disallow: /private/
Disallow: /tmp/只允许某一个爬虫访问所有目录的代码如下:
User-agent: WebCrawler
Disallow:
User-agent: *
Disallow: /以上是 robots.txt 的一些常见写法。
爬虫名称 大家可能会疑惑,爬虫名是从哪儿来的? 为什么叫这个名? 其实爬虫是有固定名字的,例如百度的爬虫就叫作 BaiduSpider。 表 2-1 列出了一些常见搜索爬虫的名称及对应的网站。
表 2-1 一些常见搜索爬虫的名称及其对应的网站
| 爬虫名称 | 网站名称 |
|---|---|
| BaiduSpider | 百度 |
| Googlebot | 谷歌 |
| 360Spider | 360 搜索 |
| YodaoBot | 有道 |
| ia_archiver | Alexa |
| Scooter | altavista |
| Bingbot | 必应 |
robotparser
了解 Robots 协议之后,就可以使用 robotparser 模块来解析 robots.txt 文件了。 该模块提供了一个类 RobotFileParser,它可以根据某网站的 robots.txt 文件判断一个爬取爬虫是否有权限爬取这个网页。
该类用起来非常简单,只需要在构造方法里传入 robots.txt 文件的链接即可。首先看一下它的声明:
urllib.robotparser.RobotFileParser(url='')当然,也可以不在声明时传入 robots.txt 文件的链接,就让其默认为空,最后再使用 set_url() 方法设置一下也可以。
下面列出了 RobotFileParser 类的几个常用方法。
set_url:用来设置 robots.txt 文件的链接。如果在创建 RobotFileParser 对象时传入了链接,就不需要使用这个方法设置了。
read:读取 robots.txt 文件并进行分析。注意,这个方法执行读取和分析操作,如果不调用这个方法,接下来的判断都会为 False,所以一定记得调用这个方法。这个方法虽不会返回任何内容,但是执行了读取操作。
parse:用来解析 robots.txt 文件,传入其中的参数是 robots.txt 文件中某些行的内容,它会按照 robots.txt 的语法规则来分析这些内容。
can_fetch:该方法有两个参数,第一个是 User-Agent,第二个是要抓取的 URL。返回结果是 True 或 False,表示 User-Agent 指示的搜索引擎是否可以抓取这个 URL。
mtime:返回上次抓取和分析 robots.txt 文件的时间,这对于长时间分析和抓取 robots.txt 文件的搜索爬虫很有必要,你可能需要定期检查以抓取最新的 robots.txt 文件。
modified:它同样对长时间分析和抓取的搜索爬虫很有帮助,可以将当前时间设置为上次抓取和分析 robots.txt 文件的时间。
下面我们用实例来看一下:
from urllib.robotparser import RobotFileParser
rp = RobotFileParser()
rp.set_url('https://www.baidu.com/robots.txt')
rp.read()
print(rp.can_fetch('Baiduspider', 'https://www.baidu.com'))
print(rp.can_fetch('Baiduspider', 'https://www.baidu.com/homepage/'))
print(rp.can_fetch('Googlebot', 'https://www.baidu.com/homepage/'))这里以百度为例,首先创建了一个 RobotFileParser 对象 rp,然后通过 set_url 方法设置了 robots.txt 文件的链接。 当然,要是不用 set_url 方法,可以在声明对象时直接用如下方法设置:
rp = RobotFileParser('https://www.baidu.com/robots.txt')接着利用 can_fetch 方法判断了网页是否可以被抓取。
运行结果如下:
True
True
False可以看到,这里我们利用 Baiduspider 可以抓取百度的首页以及 homepage 页面,但是 Googlebot 就不能抓取 homepage 页面。
打开百度的 robots.txt 文件,可以看到如下信息:
User-agent: Baiduspider
Disallow: /baiduDisallow: /s?
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: Googlebot
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh不难看出,百度的 robots.txt 文件没有限制 Baiduspider 对百度 homepage 页面的抓取,限制了 Googlebot 对 homepage 页面的抓取。
这里同样可以使用 parse 方法执行对 robots.txt 文件的读取和分析,实例如下:
from urllib.request import urlopen
from urllib.robotparser import RobotFileParser
rp = RobotFileParser()
rp.parse(urlopen('https://www.baidu.com/robots.txt').read().decode('utf-8').split('\n'))
print(rp.can_fetch('Baiduspider', 'https://www.baidu.com'))
print(rp.can_fetch('Baiduspider', 'https://www.baidu.com/homepage/'))
print(rp.can_fetch('Googlebot', 'https://www.baidu.com/homepage/'))运行结果是一样的:
True
True
False本节介绍了 robotparser 模块的基本用法和实例,利用此模块,我们可以方便地判断哪些页面能抓取、哪些页面不能。
5. 总结
本节内容比较多,我们介绍了 urllib 库的 request、error、parse、robotparser 模块的基本用法,这些是一些基础模块,有一些模块的实用性还是很强的,例如我们可以利用 parse 模块来进行 URL 的各种处理,还是很方便的。
本节代码参见: https://github.com/Python3WebSpider/UrllibTest。
2.2 requests 的使用
2.1节我们了解了 urllib 库的基本用法,其中确实有不方便的地方,例如处理网页验证和 Cookie 时,需要写 Opener 类和 Handler 类来处理。
另外实现 POST、PUT 等请求时的写法也不太方便。
为了更加方便地实现这些操作,产生了更为强大的库—————requests。有了它,Cookie、登录验证、代理设置等操作都不是事儿。
接下来,让我们领略一下 requests 库的强大之处吧。
1. 准备工作
在开始学习之前,请确保已经正确安装好 requests 库,如果尚未安装,可以使用 pip3 来安装:
pip3 install requests更加详细的安装说明可以参考 https://setup.scrape.center/requests。
2. 实例引入
urllib 库中的 urlopen 方法实际上是以 GET 方式请求网页,requests 库中相应的方法就是 get 方法,是不是感觉表意更直接一些?
下面通过实例来看一下:
import requests
r = requests.get('https://www.baidu.com/')
print(type(r))
print(r.status_code)
print(type(r.text))
print(r.text[:100])
print(r.cookies)运行结果如下:
<class 'requests.models.Response'>
<class 'str'>
<!DOCTYPE html>
<!--STATUS OK--><html> <head> <meta http-equiv=content-type content=text/html;charse
<RequestsCookieJar [<Cookie BDORZ=27315 for .baidu.com/>]>这里我们调用 get 方法实现了与 urlopen 方法相同的操作,返回一个 Response 对象,并将其存放在变量 r 中,然后分别输出了响应的类型、状态码、响应体的类型、内容,以及 Cookie。
观察运行结果可以发现,返回的响应类型是 requests.models.Response,响应体的类型是字符串 str,Cookie 的类型是 RequestsCookieJar。
使用 get 方法成功实现一个 GET 请求算不了什么,requests 库更方便之处在于其他请求类型依然可以用一句话完成,实例如下:
import requests
r = requests.get('https://www.httpbin.org/get')
r = requests.post('https://www.httpbin.org/post')
r = requests.put('https://www.httpbin.org/put')
r = requests.delete('https://www.httpbin.org/delete')
r = requests.patch('https://www.httpbin.org/patch')这里分别用 post、put、delete 等方法实现了 POST、PUT、DELETE 等请求。是不是比 urllib 库简单太多了?
其实这只是冰山一角,更多的还在后面。
3. GET 请求
HTTP 中最常见的请求之一就是 GET 请求,首先来详细了解一下利用 requests 库构建 GET 请求的方法。
基本实例
下面构建一个最简单的 GET 请求,请求的链接为 https://www.httpbin.org/get,该网站会判断客户端发起的是否为 GET 请求,如果是,那么它将返回相应的请求信息:
import requests
r = requests.get('https://www.httpbin.org/get')
print(r.text)运行结果如下:
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "www.httpbin.org",
"User-Agent": "python-requests/2.22.0",
"X-Amzn-Trace-Id": "Root=1-5e6e3a2e-6b1a28288d721c9e425a462a"
},
"origin": "17.20.233.237",
"url": "https://www.httpbin.org/get"
}可以发现,我们成功发起了GET请求,返回结果中包含请求头、URL、IP等信息。
那么,对于GET请求,如果要附加额外的信息,一般怎样添加呢?例如现在想添加两个参数 name 和 age,其中 name 是 germey、age 是25,于是URL 就可以写成如下内容:
`https://www.httpbin.org/get?name=germey&age=25`要构造这个请求链接,是不是要直接写成这样呢?
r = requests.get('https://www.httpbin.org/get?name=germey&age=25')这样也可以,但是看起来有点不人性化哎?这些参数还需要我们手动去拼接,实现起来着实不优雅。
一般情况下,我们利用 params 参数就可以直接传递这种信息了,实例如下:
import requests
data = {
'name': 'germey',
'age': 25
}
r = requests.get('https://www.httpbin.org/get', params=data)
print(r.text)运行结果如下:
{
"args": {
"age": "25",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "www.httpbin.org",
"User-Agent": "python-requests/2.10.0"
},
"origin": "122.4.215.33",
"url": "https://www.httpbin.org/get?age=22&name=germey"
}上面我们把 URL参数以字典的形式传给get方法的params参数,通过返回信息我们可以判断,请求的链接自动被构造成了https://www.httpbin.org/get?age=22&name=germey,这样我们就不用自己构造URL了,非常方便。
另外,网页的返回类型虽然是 str类型,但是它很特殊,是JSON 格式的。 所以,如果想直接解析返回结果,得到一个JSON 格式的数据,可以直接调用json方法。 实例如下:
import requests
r = requests.get('https://www.httpbin.org/get')
print(type(r.text))print(r.json())
print(type(r.json()))运行结果如下:
<class'str'>
{'headers': {'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Host': 'www.httpbin.org', 'User-Agent':
'python-requests/2.10.0'}, 'url': 'http://www.httpbin.org/get', 'args': {}, 'origin': '182.33.248.131'}
<class 'dict'>可以发现, 调用json方法可以将返回结果 (JSON 格式的字符串) 转化为字典。
但需要注意的是, 如果返回结果不是 JSON 格式, 就会出现解析错误, 抛出 json.decoder. JSONDecodeError 异常。
抓取网页
上面的请求链接返回的是 JSON 格式的字符串, 那么如果请求普通的网页, 就肯定能获得相应的内容了。
我们以一个实例页面 https://ssr1.scrape.center/ 作为演示, 往里面加入一点提取信息的逻辑, 将代码完善成如下的样子:
import requests
import re
r = requests.get('https://ssr1.scrape.center/')
pattern = re.compile('<h2.*?>(.*?)</h2>', re.S)
titles = re.findall(pattern, r.text)
print(titles)这个例子中, 我们用最基础的正则表达式来匹配所有的标题内容。 关于正则表达式, 会在 2.3 节详细介绍, 这里其只作为实例来配合讲解。
运行结果如下:
['肖申克的救赎- The Shawshank Redemption', '霸王别姬- Farewell My Concubine','泰坦尼克号 - Titanic',
'罗马假日 - Roman Holiday','这个杀手不太冷-Léon','魂断蓝桥- Waterloo Bridge','唐伯虎点秋香 - Flirting
Scholar','喜剧之王- The King of Comedy', '楚门的世界- The Truman Show', '活着 To Live']我们发现, 这里成功提取出了所有电影标题, 只需一个最基本的抓取和提取流程就完成了。
抓取二进制数据
在上面的例子中, 我们抓取的是网站的一个页面, 实际上它返回的是一个 HTML 文档。 要是想抓取图片、音频、视频等文件, 应该怎么办呢?
图片、音频、视频这些文件本质上都是由二进制码组成的, 由于有特定的保存格式和对应的解析方式, 我们才可以看到这些形形色色的多媒体。 所以, 要想抓取它们, 就必须拿到它们的二进制数据。
下面以示例网站的站点图标为例来看一下:
import requests
r = requests.get('https://scrape.center/favicon.ico')
print(r.text)
print(r.content)这里抓取的内容是站点图标, 也就是浏览器中每一个标签上显示的小图标, 如图2-3所示。

上述实例将会打印 Response 对象的两个属性,一个是 text,另一个是 content。 运行结果如图 2-4 和图 2-5 所示,分别是 r.text 和 r.content 的结果。


可以注意到,r.text 中出现了乱码,r.content 的前面带有一个 b,代表这是 bytes 类型的数据。 由于图片是二进制数据,所以前者在打印时会转化为 str 类型,也就是图片直接转化为字符串,理所当然会出现乱码。
上面的运行结果我们并不能看懂,它实际上是图片的二进制数据。不过没关系,我们将刚才提取到的信息保存下来就好了,代码如下:
import requests
r = requests.get('https://scrape.center/favicon.ico')
with open('favicon.ico', 'wb') as f:
f.write(r.content)这里用了 open 方法,其第一个参数是文件名称,第二个参数代表以二进制写的形式打开文件,可以向文件里写入二进制数据。
上述代码运行结束之后,可以发现在文件夹中出现了名为 favicon.ico 的图标,如图 2-6 所示。 这样,我们就把二进制数据成功保存成了一张图片,这个小图标被我们成功爬取下来了。 同样地,我们也可以用这种方法获取音频和视频文件。

添加请求头
我们知道,在发起 HTTP 请求的时候,会有一个请求头 Request Headers,那么怎么设置这个请求头呢?
很简单,使用 headers 参数就可以完成了。
在刚才的实例中,实际上是没有设置请求头信息的,这样的话,某些网站会发现这并不是一个由正常浏览器发起的请求,于是可能会返回异常结果,导致网页抓取失败。
要添加请求头信息,例如这里我们想添加一个 User-Agent 字段,就可以这么写:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/ 537.36'
}
r = requests.get('https://ssr1.scrape.center/', headers=headers)
print(r.text)当然,可以在这个 headers 参数中添加任意其他字段信息。
4. POST 请求
前面我们了解了最基本的 GET 请求,另外一种比较常见的请求方式是 POST。使用 requests 库实现 POST 请求同样非常简单,实例如下:
import requests
data = {'name': 'germey', 'age': '25'}
r = requests.post("https://www.httpbin.org/post", data=data)
print(r.text)这里还是请求 https://www.httpbin.org/post,该网站可以判断请求是否为 POST 方式,如果是,就返回相关的请求信息。
运行结果如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"age": "25",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "18",
"Content-Type": "application/x-www-form-urlencoded"
}
}},
"Host": "www.httpbin.org",
"User-Agent": "python-requests/2.22.0",
"X-Amzn-Trace-Id": "Root=1-5e6e3b52-0f36782ea980fce53c8c6524"
"json": null,
"origin": "17.20.232.237",
"url": "https://www.httpbin.org/post"
}可以发现,我们成功获得了返回结果,其中form部分就是提交的数据,这证明 POST请求成功发送了。
5. 响应
请求发送后,自然会得到响应。 在上面的实例中,我们使用text 和 content 获取了响应的内容。 此外,还有很多属性和方法可以用来获取其他信息,例如状态码、响应头、Cookie等。 实例如下:
import requests
r = requests.get('https://ssr1.scrape.center/')
print(type(r.status_code), r.status_code)
print(type(r.headers), r.headers)
print(type(r.cookies), r.cookies)
print(type(r.url), r.url)
print(type(r.history), r.history)这里通过 status_code 属性得到状态码、通过 headers 属性得到响应头、通过 cookies 属性得到Cookie、通过 url 属性得到URL、通过 history 属性得到请求历史。 并将得到的这些信息分别打印出来。
运行结果如下:
<class 'int'> 200
<class 'requests.structures.CaseInsensitiveDict'> {'Server': 'nginx/1.17.8', 'Date': 'Sat, 30 May 2020
16:56:40 GMT', 'Content-Type': 'text/html; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection':
'keep-alive', 'Vary': 'Accept-Encoding', 'X-Frame-Options': 'DENY', 'X-Content-Type-Options': 'nosniff',
'Strict-Transport-Security': 'max-age=15724800; includeSubDomains', 'Content-Encoding': 'gzip'}
<class 'requests.cookies.RequestsCookieJar'> <RequestsCookieJar[]>
<class 'str'> https://ssr1.scrape.center/
<class 'list'> []可以看到,headers 和 cookies 这两个属性得到的结果分别是 CaseInsensitiveDict 和 Requests-CookieJar对象。
由第1章我们知道,状态码是用来表示响应状态的,例如200代表我们得到的响应是没问题的,上面例子输出的状态码正好也是200,所以我们可以通过判断这个数字知道爬虫爬取成功了。
requests 库还提供了一个内置的状态码查询对象 requests.codes,用法实例如下:
import requests
r = requests.get('https://ssr1.scrape.center/')
exit() if not r.status_code == requests.codes.ok else print('Request Successfully')这里通过比较返回码和内置的表示成功的状态码,来保证请求是否得到了正常响应,如果是,就输出请求成功的消息,否则程序终止运行,这里我们用 requests.codes.ok得到的成功状态码是200。
这样我们就不需要再在程序里写状态码对应的数字了,用字符串表示状态码会显得更加直观。
当然,肯定不能只有ok这一个条件码。
下面列出了返回码和相应的查询条件:
信息性状态码
100: ('continue',)
101: ('switching_protocols',)
102: ('processing',)
103: ('checkpoint',)
122: ('uri_too_long', 'request_uri_too_long')成功状态码
200: ('ok', 'okay', 'all_ok', 'all_okay', 'all_good', '\o/', '')
201: ('created',)
202: ('accepted',)
203: ('non_authoritative_info', 'non_authoritative_information')
204: ('no_content',)
205: ('reset_content', 'reset')
206: ('partial_content', 'partial')
207: ('multi_status', 'multiple_status', 'multi_stati', 'multiple_stati')
208: ('already_reported',)
226: ('im_used',)重定向状态码
300: ('multiple_choices',)
301: ('moved_permanently', 'moved', '\o-')
302: ('found',)
303: ('see_other', 'other')
304: ('not_modified',)
305: ('use_proxy',)
306: ('switch_proxy',)
307: ('temporary_redirect', 'temporary_moved', 'temporary')
308: ('permanent_redirect', 'resume_incomplete', 'resume',), # These 2 to be removed in 3.0客户端错误状态码
400: ('bad_request', 'bad')
401: ('unauthorized',)
402: ('payment_required', 'payment')
403: ('forbidden',)
404: ('not_found', '-o-')
405: ('method_not_allowed', 'not_allowed')
406: ('not_acceptable',)
407: ('proxy_authentication_required', 'proxy_auth', 'proxy_authentication')
408: ('request_timeout', 'timeout')
409: ('conflict',)
410: ('gone',)
411: ('length_required',)
412: ('precondition_failed', 'precondition')
413: ('request_entity_too_large',)
414: ('request_uri_too_large',)
415: ('unsupported_media_type', 'unsupported_media', 'media_type')
416: ('requested_range_not_satisfiable', 'requested_range', 'range_not_satisfiable')
417: ('expectation_failed',)
418: ('im_a_teapot', 'teapot', 'i_am_a_teapot')
421: ('misdirected_request',)
422: ('unprocessable_entity', 'unprocessable')
423: ('locked',)
424: ('failed_dependency', 'dependency')
425: ('unordered_collection', 'unordered')
426: ('upgrade_required', 'upgrade')
428: ('precondition_required', 'precondition')
429: ('too_many_requests', 'too_many')
431: ('header_fields_too_large', 'fields_too_large')
444: ('no_response', 'none')
449: ('retry_with', 'retry')
450: ('blocked_by_windows_parental_controls', 'parental_controls')
451: ('unavailable_for_legal_reasons', 'legal_reasons')
499: ('client_closed_request',)服务端错误状态码
500: ('internal_server_error', 'server_error', '/o\\', 'x')
501: ('not_implemented',),
502: ('bad_gateway',),
503: ('service_unavailable', 'unavailable'),
504: ('gateway_timeout',),
505: ('http_version_not_supported', 'http_version'),
506: ('variant_also_negotiates',),
507: ('insufficient_storage',),
509: ('bandwidth_limit_exceeded', 'bandwidth'),
510: ('not_extended',),
511: ('network_authentication_required', 'network_auth', 'network_authentication')
例如想判断结果是不是404状态,就可以用requests.codes.not_found作为内置的状态码做比较。6. 高级用法
通过本节前面部分,我们已经了解了 requests 库的基本用法,如基本的GET、POST请求以及Response 对象。 本节我们再来了解一些requests 库的高级用法,如文件上传、Cookie设置、代理设置等。
文件上传
我们知道使用 requests 库可以模拟提交一些数据。除此之外,要是有网站需要上传文件,也可以用它来实现,非常简单,实例如下:
import requests
files = {'file': open('favicon.ico', 'rb')}
r = requests.post('https://www.httpbin.org/post', files=files)
print(r.text)在前一节,我们保存了一个文件 favicon.ico,这次就用它来模拟文件上传的过程。 需要注意,favicon.ico 需要和当前脚本保存在同一目录下。 如果手头有其他文件,当然也可以上传这些文件,更改下代码即可。
运行结果如下:
{
"args": {},
"data": "",
"files": {
"file": "data:application/octet-stream;base64, AAABAAI..."
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "6665",
"Content-Type": "multipart/form-data; boundary=41fc691282cc894f8f06adabb24f05fb",
"Host": "www.httpbin.org",
"User-Agent": "python-requests/2.22.0",
"X-Amzn-Trace-Id": "Root=1-5e6e3c0b-45b07bdd3a922e364793ef48"
},
"json": null,
"origin": "16.20.232.237",
"url": "https://www.httpbin.org/post"
}以上结果省略部分内容,上传文件后,网站会返回响应,响应中包含 files 字段和 form 字段,而form 字段是空的,这证明文件上传部分会单独用一个files 字段来标识。
Cookie 设置
前面我们使用 urllib 库处理过Cookie, 写法比较复杂,有了 requests 库以后,获取和设置 Cookie只 需一步即可完成。
我们先用一个实例看一下获取 Cookie 的过程:
import requests
r = requests.get('https://www.baidu.com')
print(r.cookies)
for key, value in r.cookies.items():
print(key + '=' + value)运行结果如下:
<RequestsCookieJar [<Cookie BDORZ=27315 for .baidu.com/>]>
BDORZ=27315这里我们首先调用 cookies 属性,成功得到 Cookie,可以发现它属于 RequestCookieJar 类型。
然后调用 items 方法将 Cookie 转化为由元组组成的列表,遍历输出每一个 Cookie 条目的名称和值,实现对 Cookie 的遍历解析。
当然,我们也可以直接用 Cookie 来维持登录状态。 下面以 GitHub 为例说明一下,首先我们登录 GitHub,然后将请求头中的 Cookie 内容复制下来,如图 2-7 所示。
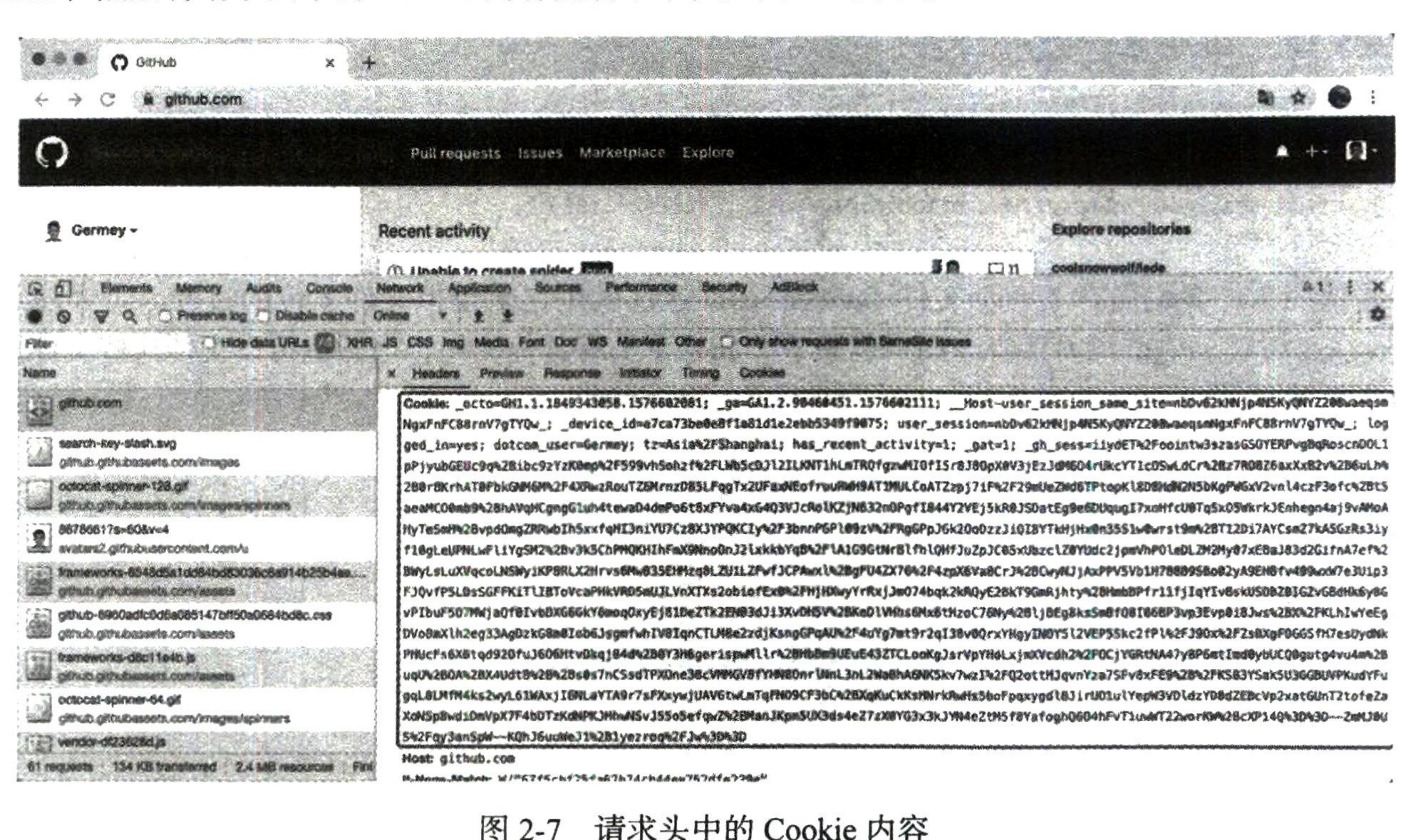
可以将图 2-7 中框起来的这部分内容替换成你自己的 Cookie,将其设置到请求头里面,然后发送请求,实例如下:
import requests
headers = {
'Cookie': '_octo-GH1.1.1849343058.1576602081; _ga=GA1.2.90460451.1576602111; Host-user_session_same_site=nbDv62kHNjp4N5KyQNYZ208waeqsmNgxFnFC88xnV7gTYQw_; _device_id=e7ca73be0e8f1a81d1e2ebb5349f9075; user_session=nbDv62kHNjp4N5KyQNYZ208waeqsmNgxFnFC88xnV7gTYQw_; logged_in=yes; dotcom_user=Germey; tz=Asia%2FShanghai; has_recent_activity=1; _gat=1; _gh_sess=your_session_info',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36',
}
r = requests.get('https://github.com/', headers=headers)
print(r.text)运行结果如图 2-8 所示。
<summary class="no-underline btn-link text-gray-dark text-bold width-full" title="Switch account
context" data-ga-click="Dashboard, click, Opened account context switcher context:user">
<img class="avatar" alt="@Germey" width="20" height="20" src="https://avatarsZ.githubusercont
ent.com/u/8678661?s=60& v.4">
<span class="css-truncate css-truncate-target ml-1">Germey</span>
<span class="dropdown-caret"></span>
</summary>
<details-menu preload class="SelectMenu Select Menu--hasFilter" aria-labelledby="context-switch-t
itle-layout" src="/dashboard/ajax.context.list?current_context-Germey">
<div class="SelectMenu-modal">
span>
<header class="SelectMenu-header">
<span class="SelectMenu-title" id="context-switch-title-layout">Switch dashboard context</
<button class="SelectMenu-closeButton" type="button" data-toggle-for-"account-switcher-lay
out"><svg aria-label="Close menu" class="octicon octicon-x" viewBox="0 0 12 16" version="1.1" widt
h="12" height="16" role="img"><path fill-rule-"evenodd" d="M7.48 813.75 3.75-1.48 1.4816 9.481-3.7
5 3.75-1.48-1.48L4.52 8.77 4.2511.48-1.4816 6.5213.75-3.75 1.48 1.487.48 8z"/></svg></button>
</header>
可以发现,结果中包含了登录后才能包含的结果,其中有我的 GitHub 用户名信息,你如果尝试 一下,同样可以得到你的用户信息。 得到这样类似的结果,说明用 Cookie 成功模拟了登录状态,这样就能爬取登录之后才能看到的 页面了。 当然,也可以通过 cookies 参数来设置 Cookie 的信息,这里我们可以构造一个 RequestsCookieJar 对象,然后对刚才复制的 Cookie 进行处理以及赋值,实例如下:
import requests
cookies = '_octo-GH1.1.1849343058.1576602081; _ga=GA1.2.90460451.1576602111;\
_Host-user_session_same_site=nbDv62kHNjp4N5KyQNYZ208waeqsmNgxFnFC88rnV7gTYQW_;\
_device_id=a7ca73be0e8f1a81d1e2ebb5349f9075; user_session=nbDv62kHNjp4N5KyQNYZ208waeqsmNgxFnFC88rnV7gTYQw_;\
logged_in=yes; dotcom_user=Germey; tz=Asia%2FShanghai; has_recent_activity=1; _gat=1;\
_gh_sess=your_session_info'
jar = requests.cookies.RequestsCookieJar()
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko)\
Chrome/53.0.2785.116 Safari/537.36'
}
for cookie in cookies.split(';'):
key, value = cookie.split('=', 1)
jar.set(key, value)
r = requests.get('https://github.com/', cookies=jar, headers=headers)
print(r.text)这里我们首先新建了一个 RequestCookieJar对象,然后利用split 方法对复制下来的Cookie 内容做分割,接着利用set方法设置好每个Cookie条目的键名和键值,最后通过调用requests 库的get方法并把 RequestCookieJar 对象通过 cookies 参数传递,最后即可获取登录后的页面。 测试后,发现同样可以正常登录。
Session 维持
直接利用 requests 库中 get 或 post方法的确可以做到模拟网页的请求,但这两种方法实际上相当 于不同的 Session,或者说是用两个浏览器打开了不同的页面。 设想这样一个场景,第一个请求利用 requests 库的 post方法登录了某个网站,第二次想获取成功 登录后的自己的个人信息,于是又用了一次 requests 库的get方法去请求个人信息页面。
这实际相当于打开了两个浏览器,是两个完全独立的操作,对应两个完全不相关的 Session,那么能够成功获取个人信息吗?当然不能。
有人可能说,在两次请求时设置一样的 Cookie 不就行了?可以,但这样做显得很烦琐,我们有更简单的解决方法。
究其原因,解决这个问题的主要方法是维持同一个 Session,也就是第二次请求的时候是打开一个新的浏览器选项卡而不是打开一个新的浏览器。 但是又不想每次都设置 Cookie,该怎么办呢?这时候出现了新的利器——Session 对象。
利用 Session 对象,我们可以方便地维护一个 Session,而且不用担心 Cookie的问题,它会自动帮我们处理好。
我们先做一个小实验吧,如果沿用之前的写法,实例如下:
import requests
requests.get('https://www.httpbin.org/cookies/set/number/123456789')
r = requests.get('https://www.httpbin.org/cookies')
print(r.text)这里我们请求了一个测试网址 https://www.httpbin.org/cookies/set/number/123456789。
请求这个网址时,设置了一个 Cookie 条目,名称是 number,内容是 123456789。
随后又请求了 https://www.httpbin.org/cookies,以获取当前的 Cookie 信息。
这样能成功获取设置的 Cookie 吗?试试看。
运行结果如下:
{
"cookies": {}
}发现并不能。 我们再用刚才所说的 Session 试试看:
import requests
s = requests.Session()
s.get('https://www.httpbin.org/cookies/set/number/123456789')
r = s.get('https://www.httpbin.org/cookies')
print(r.text)再看下运行结果:
{
"cookies": {"number": "123456789"}
}可以看到 Cookie 被成功获取了!这下能体会到同一个 Session 和不同 Session 的区别了吧! 所以,利用 Session 可以做到模拟同一个会话而不用担心 Cookie 的问题,它通常在模拟登录成功之后,进行下一步操作时用到。 Session 在平常用得非常广泛,可以用于模拟在一个浏览器中打开同一站点的不同页面,第 10 章会专门来讲解这部分内容。
SSL 证书验证
现在很多网站要求使用 HTTPS 协议,但是有些网站可能并没有设置好 HTTPS 证书,或者网站的 HTTPS 证书可能并不被 CA 机构认可,这时这些网站就可能出现 SSL 证书错误的提示。
例如这个实例网站: https://ssr2.scrape.center/, 如果用 Chrome 浏览器打开它,则会提示“您的连接不是私密连接”这样的错误,如图 2-9 所示。

我们可以在浏览器中通过一些设置来忽略证书的验证。 但是如果想用 requests 库来请求这类网站,又会遇到什么问题呢?我们用代码试一下:
import requests
response = requests.get('https://ssr2.scrape.center/')
print(response.status_code)运行结果如下:
requests.exceptions.SSLError: HTTPSConnectionPool(host='ssr2.scrape.center', port=443): Max retries exceeded
with url: / (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate
verify failed: unable to get local issuer certificate (_ssl.c:1056)')))可以看到,直接抛出了 SSLError 错误,原因是我们请求的 URL 的证书是无效的。
那如果我们一定要爬取这个网站,应该怎么做呢?可以使用 verify 参数控制是否验证证书,如果将此参数设置为 False,那么在请求时就不会再验证证书是否有效。
如果不设置 verify 参数,其默认值是 True,会自动验证。
于是我们改写代码如下:
import requests
response = requests.get('https://ssr2.scrape.center/', verify=False)
print(response.status_code)这样就能打印出请求成功的状态码了:
/usr/local/lib/python3.7/site-packages/urllib3/connectionpool.py: 857: InsecureRequestWarning: Unverified
HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.
readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecureRequestWarning)不过我们发现其中报了一个警告,它建议我们给它指定证书。我们可以通过设置忽略警告的方式来屏蔽这个警告:
import requests
from requests.packages import urllib3urllib3.disable_warnings()
response = requests.get('https://ssr2.scrape.center/', verify=False)
print(response.status_code)或者通过捕获警告到日志的方式忽略警告:
import logging
import requests
logging.captureWarnings(True)
response = requests.get('https://ssr2.scrape.center/', verify=False)
print(response.status_code)当然,我们也可以指定一个本地证书用作客户端证书,这可以是单个文件(包含密钥和证书)或一个包含两个文件路径的元组:
import requests
response = requests.get('https://ssr2.scrape.center/', cert=('/path/server.crt', '/path/server.key'))
print(response.status_code)当然,上面的代码是演示实例,我们需要有crt 和key文件,并且指定它们的路径。 另外注意,本地私有证书的key 必须是解密状态,加密状态的key是不支持的。
超时设置
在本机网络状况不好或者服务器网络响应太慢甚至无响应时,我们可能会等待特别久的时间才能接收到响应,甚至到最后因为接收不到响应而报错。
为了防止服务器不能及时响应,应该设置一个超时时间,如果超过这个时间还没有得到响应,就报错。
这需要用到 timeout 参数,其值是从发出请求到服务器返回响应的时间。
实例如下:
import requests
r = requests.get('https://www.httpbin.org/get', timeout=1)
print(r.status_code)通过这样的方式,我们可以将超时时间设置为1秒,意味着如果1秒内没有响应,就抛出异常。
实际上,请求分为两个阶段:连接 (connect) 和读取 (read)。
上面设置的 timeout 是用作连接和读取的 timeout 的总和。
如果要分别指定用作连接和读取的 timeout,则可以传入一个元组:
r = requests.get('https://www.httpbin.org/get', timeout=(5, 30))如果想永久等待,可以直接将 timeout 设置为 None,或者不设置直接留空,因为默认取值是 None。
这样的话,如果服务器还在运行,只是响应特别慢,那就慢慢等吧,它永远不会返回超时错误的。
其用法如下:
r = requests.get('https://www.httpbin.org/get', timeout=None)或直接不加参数:
r = requests.get('https://www.httpbin.org/get')身份认证
2.1 节我们讲到,在访问启用了基本身份认证的网站时(例如 https://ssr3.scrape.center/),首先会弹出一个认证窗口。
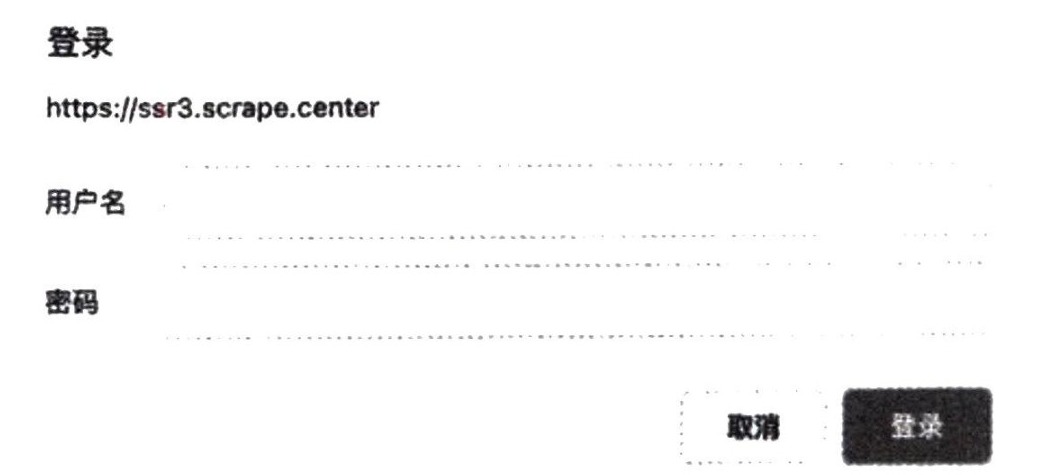
这个网站就是启用了基本身份认证,2.1 节我们可以利用 urllib 库来实现身份的校验,但实现起来相对烦琐。 那在 requests 库中怎么做呢? 当然也有办法。
我们可以使用 requests 库自带的身份认证功能,通过 auth 参数即可设置,实例如下:
import requests
from requests.auth import HTTPBasicAuth
I = requests.get('https://ssr3.scrape.center/', auth=HTTPBasicAuth('admin', 'admin'))
print(r.status_code)这个实例网站的用户名和密码都是 admin,在这里我们可以直接设置。
如果用户名和密码正确,那么请求时就会自动认证成功,返回 200 状态码;如果认证失败,则返回 401 状态码。
当然,如果参数都传一个 HTTPBasicAuth 类,就显得有点烦琐了,所以 requests 库提供了一个更简单的写法,可以直接传一个元组,它会默认使用 HTTPBasicAuth 这个类来认证。
所以上面的代码可以直接简写如下:
import requests
r = requests.get('https://ssr3.scrape.center/', auth=('admin', 'admin'))
print(r.status_code)此外,requests 库还提供了其他认证方式,如 OAuth 认证,不过此时需要安装 oauth 包,安装命令如下:
pip3 install requests_oauthlib使用 OAuth1 认证的示例方法如下:
import requests
from requests_oauthlib import OAuth1
url = 'https://api.twitter.com/1.1/account/verify_credentials.json'
auth = OAuth1('YOUR_APP_KEY', 'YOUR_APP_SECRET',
'USER_OAUTH_TOKEN', 'USER_OAUTH_TOKEN_SECRET')
requests.get(url, auth=auth)代理设置
某些网站在测试的时候请求几次,都能正常获取内容。 但是一旦开始大规模爬取,面对大规模且频繁的请求时,这些网站就可能弹出验证码,或者跳转到登录认证页面,更甚者可能会直接封禁客户端的 IP,导致在一定时间段内无法访问。
那么,为了防止这种情况发生,我们需要设置代理来解决这个问题,这时就需要用到 proxies 参数。可以用这样的方式设置:
import requestsproxies = {
'http': 'http://10.10.10.10:1080',
'https': 'http://10.10.10.10:1080',
}
requests.get('https://www.httpbin.org/get', proxies=proxies)当然,直接运行这个实例可能不行,因为这个代理可能是无效的,可以直接搜索寻找有效的代理并替换试验一下。
若代理需要使用上文所述的身份认证,可以使用类似 http://user:password@host:port 这样的语法来设置代理,实例如下:
import requests
proxies = {'https': 'http://user:password@10.10.10.10:1080/',}
requests.get('https://www.httpbin.org/get', proxies=proxies)除了基本的HTTP代理外,requests 库还支持 SOCKS 协议的代理。 首先,需要安装 socks 这个库:
pip3 install "requests[socks]"然后就可以使用SOCKS 协议代理了,实例如下:
import requests
proxies = {
'http': 'socks5://user:password@host:port',
'https': 'socks5://user:password@host:port'
}
requests.get('https://www.httpbin.org/get', proxies=proxies)Prepared Request
我们当然可以直接使用 requests 库的get 和 post 方法发送请求,但有没有想过,这个请求在requests 内部是怎么实现的呢?
实际上,requests 在发送请求的时候,是在内部构造了一个 Request 对象,并给这个对象赋予了各种参数,包括 url、headers、data 等,然后直接把这个 Request 对象发送出去,请求成功后会再得到一个 Response 对象,解析这个对象即可。
那么 Request 对象是什么类型呢?实际上它就是Prepared Request。
我们深入一下,不用get方法,直接构造一个 Prepared Request 对象来试试,代码如下:
from requests import Request, Session
url = 'https://www.httpbin.org/post'
data = {'name': 'germey'}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
s = Session()
req = Request('POST', url, data=data, headers=headers)
prepped = s.prepare_request(req)
r = s.send(prepped)
print(r.text)这里我们引入了 Request类,然后用url、data 和 headers 参数构造了一个Request对象,这时需要再调用 Session 类的 prepare_request 方法将其转换为一个 Prepared Request对象,再调用 send 方法发送,运行结果如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "www.httpbin.org",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-5e5bd6a9-6513c838f35b06a0751606d8"
},
"json": null,
"origin": "167.220.232.237",
"url": "http://www.httpbin.org/post"
}可以看到,我们达到了与POST请求同样的效果。 有了 Request 这个对象,就可以将请求当作独立的对象来看待,这样在一些场景中我们可以直接操作这个 Request 对象,更灵活地实现请求的调度和各种操作。
7. 总结
本节的 requests 库的基本用法就介绍到这里了,怎么样?有没有感觉它比 urllib 库使用起来更为方便。 本节内容需要好好掌握,后文我们会在实战中使用 requests 库完成一个网站的爬取,顺便巩固 requests 库的相关知识。 本节代码参见:https://github.com/Python3 WebSpider/RequestsTest。
2.3 正则表达式
在2.2节中,我们已经可以用requests 库来获取网页的源代码,得到HTML代码。 但我们真正想要的数据是包含在HTML 代码之中的,要怎样才能从 HTML 代码中获取想要的信息呢?正则表达式就是其中一个有效的方法。 本节我们将了解一下正则表达式的相关用法。正则表达式是用来处理字符串的强大工具,它有自己特定的语法结构,有了它,实现字符串的检索、替换、匹配验证都不在话下。 当然,对于爬虫来说,有了它,从 HTML 里提取想要的信息就非常方便了。
1. 实例引入
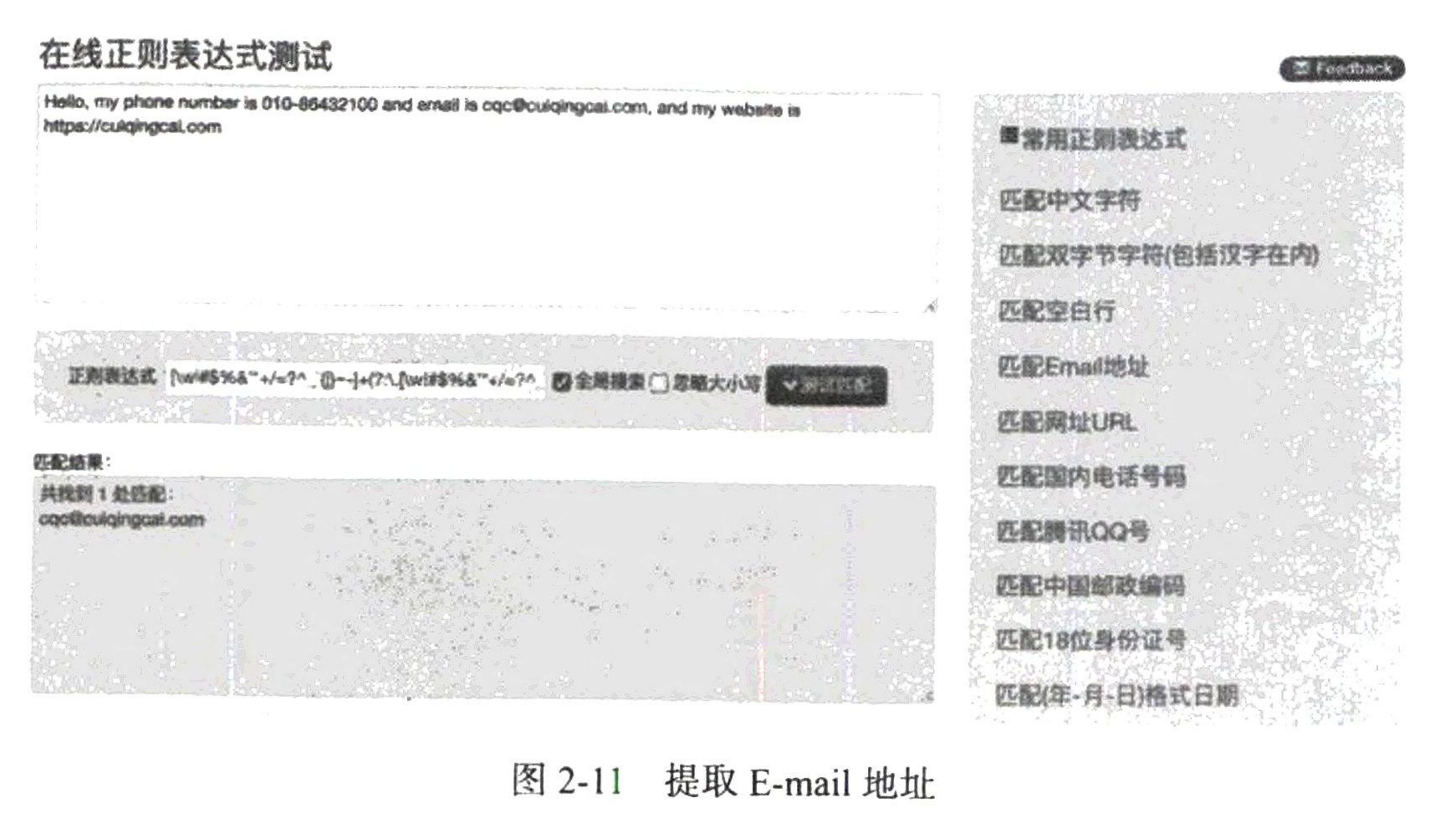
说了这么多,可能我们对正则表达式到底是什么还是比较模糊,下面就用几个实例来看一下它的用法。 打开开源中国提供的正则表达式测试工具 http://tool.oschina.net/regex/,输入待匹配的文本,然后选择常用的正则表达式,就可以得出相应的匹配结果了。 例如,这里输入如下待匹配的文本。
Hello, my phone number is 010-86432100 and email is cqc@cuiqingcai.com, and my website is https://cuiqingcai.com这段字符串中包含一个电话号码、一个E-mail地址和一个URL,接下来就尝试用正则表达式将这些内容提取出来。
在网页右侧选择“匹配Email地址”,就可以看到下方出现了文本中的E-mail,如图2-11所示。
如果选择“匹配网址URL”,可以看到下方出现了文本中的URL,如图2-12所示。

是不是非常神奇?
其实,这里就是用了正则表达式匹配,也就是用一定的规则将特定文本提取出来。 例如,E-mail地址的开头是一段字符串,然后是一个@符号,最后是某个域名,这是有特定的组成格式的。 另外,对于URL,开头是协议类型,然后是冒号加双斜线,最后是域名加路径。
对于URL来说,可以用下面的正则表达式匹配。
[a-zA-z]+://[^\s]*用这个正则表达式去匹配一个字符串,如果这个字符串中包含类似URL的文本,那么这部分就会被提取出来。
正则表达式看上去虽然是乱糟糟的一团,但里面其实是有特定语法规则的。 例如,a-z代表匹配任意的小写字母,\s代表匹配任意的空白字符,*代表匹配前面的任意多个字符,那一长串正则表达式就是这么多匹配规则的组合。
写好正则表达式后,就可以拿它去一个长字符串里匹配查找了。 不论这个字符串里面有什么,只要符合我们写的规则,统统可以找出来。 对于网页来说,如果想找出网页源代码里有多少URL,只要用匹配URL的正则表达式去匹配即可。
上面我们介绍了几个匹配规则,表2-2列出了常用的一些匹配规则。
表2-2 常用的匹配规则
| 模 式 | 描 述 | |
|---|---|---|
| `\w` | 匹配字母、数字及下划线 | |
| `\W` | 匹配不是字母、数字及下划线的字符 | |
| `\s` | 匹配任意空白字符,等价于`[\t\n\r\f]` | |
| `\S` | 匹配任意非空字符 | |
| `\d` | 匹配任意数字,等价于`[0-9]` | |
| `\D` | 匹配任意非数字的字符 | |
| `\A` | 匹配字符串开头 | |
| `\Z` | 匹配字符串结尾。如果存在换行,只匹配到换行前的结束字符串 | |
| `\z` | 匹配字符串结尾。如果存在换行,同时还会匹配换行符 | |
| `\G` | 匹配最后匹配完成的位置 | |
| `\n` | 匹配一个换行符 | |
| `\t` | 匹配一个制表符 | |
| `^` | 匹配一行字符串的开头 | |
| `$` | 匹配一行字符串的结尾 | |
| `.` | 匹配任意字符,除了换行符,当`re.DOTALL`标记被指定时,可以匹配包括换行符的任意字符 | |
| `[...]` | 用来表示一组字符,单独列出,例如`[amk]`用来匹配a、m或k | |
| `[^...]` | 匹配不在`[]`中的字符,例如匹配除了a、b、c之外的字符 | |
| `*` | 匹配0个或多个表达式 | |
| `+` | 匹配1个或多个表达式 | |
| `?` | 匹配0个或1个前面的正则表达式定义的片段,非贪婪方式 | |
| `{n}` | 精确匹配`n`个前面的表达式 | |
| `{n, m}` | 匹配`n`到`m`次由前面正则表达式定义的片段,贪婪方式 | |
| `a | b` | 匹配a或b |
| `()` | 匹配括号内的表达式,也表示一个组 |
看完这个表之后,可能有点晕晕的吧,不用担心,后面我们会详细讲解一些常见规则的用法。
其实正则表达式并非Python独有,它也可以用在其他编程语言中。
但是Python的re库提供了整个正则表达式的实现,利用这个库,可以在Python中方便地使用正则表达式。
用Python编写正则表达式时几乎都会使用这个库,下面就来了解它的一些常用方法。
2. match
这里首先介绍第一个常用的匹配方法——————match,向它传入要匹配的字符串以及正则表达式,就可以检测这个正则表达式是否和字符串相匹配。
match方法会尝试从字符串的起始位置开始匹配正则表达式,如果匹配,就返回匹配成功的结果;如果不匹配,就返回None。实例如下:
达式:
import re
content = 'Hello 123 4567 World This is a Regex Demo'
print(len(content))
result = re.match('^Hello\s\d\d\d\s\d{4}\s\w{10}', content)
print(result)
print(result.group())
print(result.span())运行结果如下:
<_sre.SRE_Match object; span=(0, 25), match= 'Hello 123 4567 World_This'>
Hello 123 4567 World_This
(0, 25)这个实例首先声明了一个字符串,其中包含英文字母、空白字符、数字等。接着写了一个正则表
`^Hello\s\d\d\d\s\d{4}\s\w{10}`用它来匹配声明的那个长字符串。开头的^表示匹配字符串的开头,也就是以Hello开头;然后
\s表示匹配空白字符,用来匹配目标字符串里Hello后面的空格;\d表示匹配数字,3个\d用来匹配123;紧接着的1个\s表示匹配空格;目标字符串的后面还有4567,我们其实依然可以用4个\d来匹配,但是这么写比较烦琐,所以可以用\d后面跟{4}的形式代表匹配4次数字;后面又是1个空白字符,最后\w{10}则表示匹配10个字母及下划线。我们注意到,这里其实并没有把目标字符串匹配完,不过这样依然可以进行匹配,只是匹配结果短一点而已。
在match方法中,第一个参数是传入了正则表达式,第二个参数是传入了要匹配的字符串。
将输出结果打印出来,可以看到结果是SRE_Match对象,证明匹配成功。该对象包含两个方法:
group方法可以输出匹配到的内容,结果是Hello 123 4567 World_This,这恰好是正则表达式按照规则匹配的内容;span方法可以输出匹配的范围,结果是(0,25),这是匹配到的结果字符串在原字符串中的位置范围。
通过上面的例子,我们基本了解了如何在Python中使用正则表达式来匹配一段文字。
匹配目标
用match方法可以实现匹配,如果想从字符串中提取一部分内容,该怎么办呢?就像上一节的实
例一样,从一段文本中提取出E-mail地址或电话号码。
可以使用括号()将想提取的子字符串括起来。()实际上标记了一个子表达式的开始和结束位置,
被标记的每个子表达式依次对应每个分组,调用group方法传入分组的索引即可获取提取结果。实例
如下:
import re
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^Hello\s(\d+)\sWorld', content)
print(result)
print(result.group())
print(result.group(1))
print(result.span())通过这个实例,我们把字符串中的1234567提取出来了,可以看到其中数字部分的正则表达式被()
括了起来。然后调用group(1)获取了匹配结果。
运行结果如下:
<_sre.SRE_Match object; span=(0, 19), match= 'Hello 1234567 World'>Hello 1234567 World 1234567 (0, 19)
可以看到,我们成功得到了1234567。 这里用的是group(1),它与group()有所不同,后者会输出完整的匹配结果,前者会输出第一个被()包围的匹配结果。 假如正则表达式后面还有用()包围的内容,那么可以依次用 group(2)、group(3)等获取。
通用匹配
刚才我们写的正则表达式其实比较复杂,只要出现空白字符就需要写 \s 匹配,出现数字就需要写\d匹配,这样的工作量非常大。
其实完全没必要这么做,因为还有一个万能匹配可以用,就是.*。
其中,可以匹配任意字符(除换行符),*代表匹配前面的字符无限次,所以它们组合在一起就可以匹配任意字符了。
有了它,我们就不用挨个字符进行匹配了。
接着上面的例子,我们利用.*改写一下正则表达式:
import re
content = 'Hello 123 4567 World_This is a Regex Demo'
result = re.match('^Hello.*Demo$', content)
print(result)
print(result.group())
print(result.span())这里我们直接省略中间部分,全部用.*来代替,并在最后加一个结尾字符串。运行结果如下:
<_sre.SRE_Match object; span=(0, 41), match='Hello 123 4567 World_This is a Regex Demo'>
Hello 123 4567 World_This is a Regex Demo
(0, 41)可以看到,group 方法输出了匹配的全部字符串,也就是说我们写的正则表达式匹配到了目标字符串的全部内容;span方法输出(0,41),这是整个字符串的长度。
因此,使用.*能够简化正则表达式的书写。
贪婪与非贪婪
使用通用匹配.*匹配到的内容有时候并不是我们想要的结果。看下面的例子:
import re
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*(\d+).*Demo$', content)
print(result)
print(result.group(1))这里我们依然想获取目标字符串中间的数字,所以正则表达式中间写的依然是(\d+)。
而数字两侧由于内容比较杂乱,所以想省略来写,于是都写成.*。
最后,组成^He.*(\d+).*Demo$,看样子没什么问题。
可我们看下运行结果:
<_sre.SRE_Match object; span=(0, 40), match='Hello 1234567 World_This is a Regex Demo'>奇怪的事情发生了,只得到了7这个数字,这是怎么回事?
这里涉及贪婪匹配和非贪婪匹配的问题。
在贪婪匹配下,.*会匹配尽可能多的字符。
正则表达式中.*后面是\d+,也就是至少一个数字,而且没有指定具体几个数字,因此,.*会匹配尽可能多的字符,
这里就把123456都匹配了,只给\d+留下一个可满足条件的数字7,因此最后得到的内容就只有数字7。
但这很明显会给我们带来很大的不便。有时候,匹配结果会莫名其妙少一部分内容。其实,这里
只需要使用非贪婪匹配就好了。非贪婪匹配的写法是.*?,比通用匹配多了一个?,那么它可以起到怎样的效果?我们再用实例看一下:
import re
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*?(\d+).*?Demo$', content)
print(result)
print(result.group(1))这里我们只是将第一个.*改成了.*?,贪婪匹配就转变为了非贪婪匹配。结果如下:
<_sre.SRE_Match object; span=(0, 40), match='Hello 1234567 World_This is a Regex Demo'>
1234567此时便可以成功获取1234567了。
原因可想而知,贪婪匹配是匹配尽可能多的字符,非贪婪匹配就是匹配尽可能少的字符。
当.*?匹配到Hello后面的空白字符时,再往后的字符就是数字了,而\d+恰好可以匹配,于是这里.*?就不再进行匹配了,而是交给\d+去匹配。
最后.*?匹配了尽可能少的字符,\d+的结果就是1234567。
所以说,在做匹配的时候,字符串中间尽量使用非贪婪匹配,也就是用.*?代替.*,以免出现匹配结果缺失的情况。
但这里需要注意,如果匹配的结果在字符串结尾,.*?有可能匹配不到任何内容了,因为它会匹配尽可能少的字符。例如:
import re
content = 'http://weibo.com/comment/kEraCN'
result1 = re.match('http.*?comment/(.*?)', content)
result2 = re.match('http.*?comment/(.*)', content)
print('result1', result1.group(1))
print('result2', result2.group(1))运行结果如下:
result1
result2 kEraCN可以观察到,.*?没有匹配到任何结果,而.*则是尽量多匹配内容,成功得到了匹配结果。
修饰符
在正则表达式中,可以用一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。我们用实例来看一下:
import re
content = '''Hello 1234567 World_This
is a Regex Demo
...
'''
result = re.match('^He.*?(\d+).*?Demo$', content)
print(result.group(1))和上面的例子相仿,我们在字符串中加了换行符,正则表达式还是一样的,用来匹配其中的数字。看一下运行结果:
AttributeError Traceback (most recent call last)
<ipython-input-18-c7d232b939645> in <module>()
6 result = re.match('^He.*?(\d+).*?Demo$', content)
----> 7 print(result.group(1))
AttributeError: 'NoneType' object has no attribute 'group'发现运行直接报错,也就是说正则表达式没有匹配到这个字符串,返回结果为None,而我们又调用了 group 方法,导致 AttributeError。
那么,为什么加了一个换行符,就匹配不到了呢?这是因为匹配的内容是除换行符之外的任意字符,当遇到换行符时,.*? 就不能匹配了,所以导致匹配失败。
这里只需加一个修饰符 re.S,即可修正这个错误:
result = re.match('^He.*?(\d+).*?Demo$', content, re.S)这个修饰符的作用是使匹配内容包括换行符在內的所有字符。此时运行结果如下:
1234567这个 re.S 在网页匹配中经常用到。因为 HTML 节点经常会有换行,加上它,就可以匹配节点与节点之间的换行了。
另外,还有一些修饰符,在必要的情况下也可以使用,如表2-3所示。
表2-3 修饰符
| 修饰符 | 描述 |
|---|---|
| `re.I` | 使匹配对大小写不敏感 |
| `re.L` | 实现本地化识别(`locale-aware`)匹配 |
| `re.M` | 多行匹配,影响`^`和`$` |
| `re.S` | 使匹配内容包括换行符在内的所有字符 |
| `re.U` | 根据 Unicode 字符集解析字符。这个标志会影响`\w`、`\W`、`\b`和`\B` |
| `re.X` | 该标志能够给予你更灵活的格式,以便将正则表达式书写得更易于理解 |
在网页匹配中,较为常用的有 re.S 和 re.I。
转义匹配
我们知道正则表达式定义了许多匹配模式,如,用于匹配除换行符以外的任意字符。但如果目标字符串里面就包含 . 这个字符,那该怎么办呢?
这时需要用到转义匹配,实例如下:
import re
content = '(百度) www.baidu.com'
result = re.match('\(百度\) www\.baidu\.com', content)
print(result)当在目标字符串中遇到用作正则匹配模式的特殊字符时,在此字符前面加反斜线\转义一下即可。
例如\. 就可以用来匹配.,运行结果如下:
<_sre.SRE_Match object; span=(0, 17), match='(百度) www.baidu.com'>可以看到,这里成功匹配到了原字符串。 以上这些是写正则表达式时常用的几个知识点,熟练掌握它们对后面非常有帮助。
3. search
前文提到过,match 方法是从字符串的开头开始匹配的,意味着一旦开头不匹配,整个匹配就失败了。我们看下面的例子:
import re
content = 'Extra stings Hello 1234567 World_This is a Regex Demo Extra stings'
result = re.match('Hello.*?(\d+).*?Demo', content)
print(result)这里的字符串以Extra 开头,正则表达式却以 Hello开头,其实整个正则表达式是字符串的一部分,但这样匹配是失败的。运行结果如下:
None因为 match 方法在使用时需要考虑目标字符串开头的内容,因此在做匹配时并不方便。它更适合检测某个字符串是否符合某个正则表达式的规则。
这里就有另外一个方法 search,它在匹配时会扫描整个字符串,然后返回第一个匹配成功的结果。
也就是说,正则表达式可以是字符串的一部分。
在匹配时,search 方法会依次以每个字符作为开头扫描字符串,直到找到第一个符合规则的字符串,然后返回匹配内容;如果扫描完还没有找到符合规则的字符串,就返回 None。
我们把上面代码中的 match 方法修改成 search,再看下运行结果:
<_sre.SRE_Match object; span=(13, 53), match= 'Hello 1234567 World_This is a Regex Demo'>
1234567这时就得到了匹配结果。
因此,为了匹配方便,尽量使用 search 方法。
下面再用几个实例来看看 search 方法的用法。
首先,这里有一段待匹配的HTML 文本,接下来写几个正则表达式实例实现相应信息的提取:
html = '''<div id="songs-list">
<h2 class="title">经典老歌</h2>
<p class="introduction">
经典老歌列表
</p>
<ul id="list" class="list-group">
<li data-view="2">一路上有你</li>
<li data-view="7">
<a href="/2.mp3" singer="任贤齐">沧海一声笑</a>
</li>
<li data-view="4" class="active">
<a href="/3.mp3" singer="齐秦">往事随风</a>
</li>
<li data-view="6"><a href="/4.mp3" singer="beyond">光辉岁月</a></li>
<li data-view="5"><a href="/5.mp3" singer="陈慧琳">记事本</a></li>
<li data-view="5">
<a href="/6.mp3" singer="邓丽君">但愿人长久</a>
</li>
</ul>
</div>'''可以观察到,ul 节点里有许多 li 节点,这些 li 节点中有的包含 a 节点,有的不包含。
a 节点还有一些相应的属性——超链接和歌手名。
首先,我们尝试提取 class 为 active 的 li 节点内部的超链接包含的歌手名和歌名,也就是说需要提取第三个 li 节点下 a 节点的 singer 属性和文本。
此时正则表达式可以以 li 开头,然后寻找一个标志符 active,中间的部分可以用 .*? 来匹配。
接下来,因为要提取 singer 这个属性值,所以还需要写入 singer="(.*?)",这里把需要提取的部分用小括号括了起来,
以便用 group 方法提取出来,小括号的两侧边界是双引号。
然后还需要匹配 a 节点的文本,此文本的左边界是 >,右边界是 </a>。
然后目标内容依然用(.*?)来匹配,所以最后的正则表达式就变成了:
<li.*?active.*?singer="(.*?)">(.*?)</a>再调用 search 方法,它会搜索整个HTML文本,找到符合上述正则表达式的第一个内容并返回。
另外,由于代码中有换行,所以 search 方法的第三个参数需要传入 re.S。于是整个匹配代码如下:
result = re.search('<li.*?active.*?singer="(.*?)">(.*?)</a>', html, re.S)
if result:
print(result.group(1), result.group(2))由于需要获取的歌手和歌名都已经用小括号包围,所以可以用 group 方法获取。
运行结果如下:
齐秦 往事随风可以看到,这正是 class 为 active 的 li 节点内部的超链接包含的歌手名和歌名。
如果正则表达式不加 active (也就是匹配不带 class 为 active 的节点内容),会怎样呢?我们将正则表达式中的 active 去掉,代码改写如下:
result = re.search('<li.*?singer="(.*?)">(.*?)</a>', html, re.S)
if result:
print(result.group(1), result.group(2))由于 search 方法会返回第一个符合条件的匹配目标,于是这里结果就变了:
任贤齐 沧海一声笑把 active 标签去掉后,从字符串开头开始搜索,此时符合条件的节点就变成了第二个 li 节点,后面的就不再匹配,所以运行结果就变成第二个 li 节点中的内容。
注意,在上面的两次匹配中,search 方法的第三个参数都加了 re.S,这使得 .*? 可以匹配换行,所以含有换行的 li 节点被匹配到了。
如果我们将其去掉,结果会是什么?去掉 re.S 的代码如下:
result = re.search('<li.*?singer="(.*?)">(.*?)</a>', html)
if result:
print(result.group(1), result.group(2))运行结果如下:
beyond 光辉岁月可以看到,结果变成了第四个 li 节点的内容。
这是因为第二个和第三个 li 节点都包含换行符,去掉 re.S 之后,.*? 已经不能匹配换行符,
所以正则表达式不会匹配这两个 li 节点,而第四个 li 节点中不包含换行符,可以成功匹配。
由于绝大部分 HTML 文本包含换行符,所以需要尽量加上 re.S 修饰符,以免出现匹配不到的问题。
4. findall
介绍完了 search 方法的用法,它可以返回与正则表达式相匹配的第一个字符串。
如果想要获取与正则表达式相匹配的所有字符串,该如何处理呢?这就要借助 findall 方法了。
还是用上面的 HTML 文本,如果想获取其中所有 a 节点的超链接、歌手和歌名,可以将 search 方法换成 findall 方法。
其返回结果是列表类型,需要通过遍历来依次获取每组内容。
代码如下:
results = re.findall('<li.*?href="(.*?)".*?singer="(.*?)">(.*?)</a>', html, re.S)
print(results)
print(type(results))
for result in results:
print(result)
print(result[0], result[1], result[2])运行结果如下:
[('/2.mp3', '任贤齐', '沧海一声笑'), ('/3.mp3', '齐秦', '往事随风'), ('/4.mp3', 'beyond', '光辉岁月'), ('/5.mp3', '陈慧琳', '记事本'), ('/6.mp3', '邓丽君', '但愿人长久')]
<class 'list'>
('/2.mp3', '任贤齐', '沧海一声笑')
/2.mp3 任贤齐 沧海一声笑
('/3.mp3','齐秦','往事随风')
/3.mp3 齐秦 往事随风
('/4.mp3', 'beyond','光辉岁月')
/4.mp3 beyond 光辉岁月
('15.mp3','陈慧琳','记事本')
/5.mp3 陈慧琳 记事本
('/6.mp3','邓丽君','但愿人长久')
/6.mp3 邓丽君 但愿人长久可以看到,返回的列表中的每个元素都是元组类型,我们用索引依次取出每个条目即可。
总结一下,如果只想获取匹配到的第一个字符串,可以用search方法;如果需要提取多个内容,可以用 findall 方法。
5. sub
除了使用正则表达式提取信息,有时候还需要借助它来修改文本。
例如,想要把一串文本中的所有数字都去掉,如果只用字符串的replace方法,未免太烦琐了,这时可以借助 sub 方法。
实例如下:
import re
content = '54aK54yr50iR54ix5L2g'
content = re.sub('\d+', '', content)
print(content)运行结果如下:
aKyroiRixLg这里往 sub 方法的第一个参数中传入\d+以匹配所有的数字,往第二个参数中传入把数字替换成的字符串(如果去掉该参数,可以赋值为空),第三个参数是原字符串。
在上面的HTML文本中,如果想获取所有li节点的歌名,直接用正则表达式来提取可能比较烦琐。例如,写成这样:
results = re.findall('<li.*?>\s*?(<a.*?>)?(\w+)(</a>)?\s*?</li>', html, re.S)
for result in results:
print(result[1])运行结果如下:
一路上有你
沧海一声笑
往事随风
光辉岁月
记事本
但愿人长久而此时借助 sub 方法就比较简单了。可以先用sub方法将a节点去掉,只留下文本,然后再利用findall 提取就好了:
html = re.sub('<a.*?>|</a>', '', html)
print(html)
results = re.findall('<li.*?>(.*?)</li>', html, re.S)
for result in results:
print(result.strip())运行结果如下:
<div id="songs-list">
<h2 class="title">经典老歌</h2>
<p class="introduction">
经典老歌列表
</p>
<ul id="list" class="list-group">
<li data-view="2">一路上有你</li>
<li data-view="7">
沧海一声笑
</li>
<li data-view="4" class="active">
往事随风
</li>
<li data-view="6">光辉岁月 </li>
<li data-view="5"> 记事本 </li>
<li data-view="5">
但愿人长久
</li>
</ul>
</div>
一路上有你
沧海一声笑
往事随风
光辉岁月
记事本
但愿人长久可以看到,经过 sub 方法处理后,a 节点就没有了,然后通过 findall 方法直接提取即可。
可以发现,在适当的时候借助 sub 方法,可以起到事半功倍的效果。
6. compile
前面所讲的方法都是用来处理字符串的方法,最后再介绍一下 compile 方法,这个方法可以将正则字符串编译成正则表达式对象,以便在后面的匹配中复用。
实例代码如下:
import re
content1 = '2019-12-15 12:00'
content2 = '2019-12-17 12:55'
content3 = '2019-12-22 13:21'
pattern = re.compile('\d{2}:\d{2}')
result1 = re.sub(pattern, '', content1)
result2= re.sub(pattern, '', content2)
result3 = re.sub(pattern, '', content3)
print(result1, result2, result3)这个实例里有 3 个日期,我们想分别将这 3 个日期中的时间去掉,这时可以借助 sub 方法。
该方法的第一个参数是正则表达式,但是这里没有必要重复写 3 个同样的正则表达式,此时就可以借助 compile 方法将正则表达式编译成一个正则表达式对象,以便复用。
运行结果如下:
2019-12-15 2019-12-17 2019-12-22另外, compile 还可以传入修饰符,例如 re.S 等修饰符,这样在 search、findall 等方法中就不需要额外传了。
所以,可以说 compile 方法是给正则表达式做了一层封装,以便我们更好地复用。
7. 总结
到此为止,正则表达式的基本用法就介绍完了,后面会通过具体的实例来巩固这些方法。 本节代码参见:https://github.com/Python3WebSpider/RegexTest。
2.4 httpx 的使用
前面我们介绍了 urllib 库和 requests 库的使用,已经可以爬取绝大多数网站的数据,但对于某些网站依然无能为力。
什么情况?这些网站强制使用 HTTP/2.0 协议访问,这时 urllib 和 requests 是无法爬取数据的,因为它们只支持 HTTP/1.1,不支持 HTTP/2.0。
那这种情况下应该怎么办呢?
还是有办法的,只需要使用一些支持 HTTP/2.0 的请求库就好了,目前来说,比较有代表性的是 hyper 和 httpx,后者使用起来更加方便,功能也更强大,requests 已有的功能它几乎都支持。 本节我们介绍 httpx 的使用。
1. 示例
下面我们来看一个案例,https://spa16.scrape.center/ 就是强制使用 HTTP/2.0 访问的一个网站,用浏览器打开此网站,查看 Network 面板,可以看到 Protocol 一列都是 h2,证明请求所用的协议是 HTTP/2.0,如图2-13所示。

这个网站用 requests 是无法爬取的,不妨来尝试一下:
import requests
url = 'https://spa16.scrape.center/'
response = requests.get(url)
print(response.text)运行结果如下:
Traceback (most recent call last):
raise RemoteDisconnected("Remote end closed connection without"
http.client.RemoteDisconnected: Remote end closed connection without response
requests.exceptions.ProxyError: HTTPSConnectionPool (host='spa16.scrape.center', port=443): Max retries
exceeded with url: / (Caused by ProxyError('Cannot connect to proxy.', RemoteDisconnected('Remote end closed
connection without response')))可以看到,首先抛出的就是 RemoteDisconnected 错误,请求失败。 可能有人认为这是没有设置请求头导致的,其实不是,真实原因是 requests 这个库是使用 HTTP/1.1 访问的目标网站,而目标网站会检测请求使用的协议是不是 HTTP/2.0,如果不是就拒绝返回任何结果。
2. 安装
httpx 可以直接使用 pip3 工具安装,所需的 Python 版本是 3.6 及以上,安装命令如下:
pip3 install httpx 但这样安装完的 httpx 是不支持 HTTP/2.0 的,如果想支持,可以这样安装:
pip3 install 'httpx[http2]'这样就既安装了 httpx, 又安装了 httpx 对 HTTP/2.0 的支持模块。
3. 基本使用
httpx 和 requests 的很多 API 存在相似之处,我们先看下最基本的 GET 请求的用法:
import httpx
response = httpx.get('https://www.httpbin.org/get')
print(response.status_code)
print(response.headers)
print(response.text)这里我们还是请求之前的测试网站,直接使用 httpx 的 get 方法即可,用法和 requests 里的一模一样,将返回结果赋值为 response 变量,然后打印出它的 status\_code、headers、text 等属性,运行结果如下:
Headers({'date': 'Mon, 17 May 2021 15:54:06 GMT', 'content-type': 'application/json', 'content-length': '305', 'connection': 'keep-alive', 'server': 'gunicorn/19.9.0', 'access-control-allow-origin': '*', 'access-control-allow-credentials': 'true'})
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "www.httpbin.org",
"User-Agent": "python-httpx/0.18.1",
"X-Amzn-Trace-Id": "Root=1-60a2919e-7cab90d911d813877e6e4e84"
},
"origin": "203.184.131.36",
"url": "https://www.httpbin.org/get"
}输出结果包含三项内容,status\_code 属性对应状态码,为 200; headers 属性对应响应头,是一个 Headers 对象,类似于一个字典; text 属性对应响应体,可以看到其中的 User-Agent 是 python-httpx/0.18.1,代表我们是用 httpx 请求的。
下面换一个 User-Agent 再请求一次,代码改写如下:
import httpx
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
response = httpx.get('https://www.httpbin.org/get', headers=headers)
print(response.text)这里我们换了一个 User-Agent 重新请求,并将其赋值为 headers 变量,然后传递给 headers 参数,运行结果如下:
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "www.httpbin.org",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36","X-Amzn-Trace-Id": "Root=1-60a293b9-1042225a73778881454d1f62"
},
}"origin": "203.184.131.36", "url": "https://www.httpbin.org/get" 可以发现更换后的User-Agent 生效了。 回到本节开头提到的示例网站,我们试着用httpx请求一下这个网站,看看效果如何,代码如下:
import httpx
response = httpx.get('https://spa16.scrape.center')
print(response.text)运行结果如下:
Traceback (most recent call last):
...
raise RemoteProtocolError (msg)
httpcore. RemoteProtocolError: Server disconnected without sending a response.
The above exception was the direct cause of the following exception:
...
raise mapped_exc(message) from exc httpx. Remote ProtocolError: Server disconnected without sending a response.可以看到,抛出了和使用requests 请求时类似的错误,不是说好支持HTTP/2.0吗?其实,httpx 默 认是不会开启对HTTP/2.0的支持的,默认使用的是HTTP/1.1,需要手动声明一下才能使用HTTP/2.0, 代码改写如下:
import httpx
client = httpx.Client(http2=True)
response = client.get('https://spa16.scrape.center/')
print(response.text)运行结果如下:
<!DOCTYPE html><html lang=en><head><meta charset=utf-8><meta http-equiv=X-UA-Compatible
content="IE=edge"><meta name=viewport content="width=device-width, initial-scale=1"><meta name=referrer
content=no-referrer><link rel=icon href=/favicon.ico><title>Scrape | Book</title><link
href=/css/chunk-50522e84.e4e1dae6.css rel=prefetch><link href=/css/chunk-f52d396c.4f574d24.css
rel=prefetch><link href=/js/chunk-50522e84.6b3e24aa.js rel-prefetch><link
href=/js/chunk-f52d396c.f8f41620.js rel-prefetch><link href=/css/app.ea9d802a.css rel=preload
as=style><link href=/js/app.b93891e2.js rel-preload as=script><link href=/js/chunk-vendors.a02ff921.js
rel=preload as=script><link href=/css/app.ea9d802a.css rel=stylesheet></head><body><noscript><strong>We're
sorry but portal doesn't work properly without JavaScript enabled. Please enable it to
continue.</strong></noscript><div id=app></div><script src=/js/chunk-vendors.a02ff921.js></script><script
src=/js/app.b93891e2.js></script></body></html>这里我们声明了一个Client对象,赋值为client 变量,同时显式地将http2参数设置为True, 这样便开启了对HTTP/2.0的支持,之后就会发现可以成功获取HTML代码了。这也就印证了这个示 例网站只能使用HTTP/2.0 访问。 刚才我们也提到了,httpx和requests 有很多相似的API,上面实现的是GET请求,对于POST请 求、PUT请求和DELETE 请求来说,实现方式是类似的:
import httpx
r = httpx.get('https://www.httpbin.org/get', params={'name': 'germey'})
r = httpx.post('https://www.httpbin.org/post', data={'name': 'germey'})
r = httpx.put('https://www.httpbin.org/put')
r = httpx.delete('https://www.httpbin.org/delete')
r = httpx.patch('https://www.httpbin.org/patch')基于得到的 Response 对象,可以使用如下属性和方法获取想要的内容。
status_code:状态码。
text:响应体的文本内容。
content:响应体的二进制内容,当请求的目标是二进制数据(如图片)时,可以使用此属性获取。
headers:响应头,是 Headers 对象,可以用像获取字典中的内容一样获取其中某个 Header 的值。
json:方法,可以调用此方法将文本结果转化为 JSON 对象。
除了这些,httpx 还有一些基本用法也和 requests 极其类似,这里就不再赘述了,可以参考官方文档: https://www.python-httpx.org/quickstart/。
4. Client 对象
httpx 中有一些基本的 API 和 requests 中的非常相似,但也有一些 API 是不相似的,例如 httpx 中有一个 Client 对象,就可以和 requests 中的 Session 对象类比学习。
下面我们介绍 Client 对象的使用。官方比较推荐的使用方式是 with as 语句,示例如下:
import httpx
with httpx.Client() as client:
response = client.get('https://www.httpbin.org/get')
print(response)运行结果如下:
<Response [200 OK]>这个用法等价于:
import httpx
client = httpx.Client()
try:
response = client.get('https://www.httpbin.org/get')
finally:
client.close()两种方式的运行结果是一样的,只不过这里需要我们在最后显式地调用 close 方法来关闭 Client 对象。
另外,在声明 Client 对象时可以指定一些参数,例如 headers,这样使用该对象发起的所有请求都会默认带上这些参数配置,示例如下:
import httpx
url = 'http://www.httpbin.org/headers'
headers = {'User-Agent': 'my-app/0.0.1'}
with httpx.Client (headers=headers) as client:
r = client.get(url)
print(r.json()['headers']['User-Agent'])这里我们声明了一个 headers 变量,内容为 User-Agent 属性,然后将此变量传递给 headers 参数初始化了一个 Client 对象,并赋值为 client 变量,最后用 client 变量请求了测试网站,并打印返回结果中的 User-Agent 的内容:
my-app/0.0.1可以看到,headers 成功赋值了。
关于 Client 对象的更多高级用法可以参考官方文档: https://www.python-httpx.org/advanced/。
5. 支持 HTTP/2.0
现在是要在客户端上开启对 HTTP/2.0 的支持,就像“基本使用”小节所说的那样,同样是声明
Client 对象,然后将 http2 参数设置为 True,如果不设置,那么默认支持 HTTP/1.1,即不开启对 HTTP/2.0 的支持。
写法如下:
import httpx
client = httpx.Client(http2=True)
response = client.get('https://www.httpbin.org/get')
print(response.text)
print(response.http_version)这里我们输出了 response 变量的 http_version 属性,这是 requests 中不存在的属性,其结果可能为:
"HTTP/1.0", "HTTP/1.1", "HTTP/2"。
这里输出的 http_version 属性值是 HTTP/2,代表使用了 HTTP/2.0 协议传输。
如果客户端连接到仅支持 HTTP/1.1 的服务器,那么它也需要改用 HTTP/1.1。
6. 支持异步请求
httpx 还支持异步客户端请求 (即 AsyncClient),支持 Python 的 async 请求模式,写法如下:
import httpx
import asyncio
async def fetch(url):
async with httpx.AsyncClient(http2=True) as client:
response = await client.get(url)
print(response.text)
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(fetch('https://www.httpbin.org/get'))关于异步请求,目前仅了解一下即可,后面章节也会专门对异步请求进行讲解。 大家也可以参考官方文档: https://www.python-httpx.org/async/。
7. 总结
本节介绍了 httpx 的基本用法,该库的 API 与 requests 的非常相似,简单易用,同时支持 HTTP/2.0,推荐大家使用。
本节代码参见: https://github.com/Python3WebSpider/HttpxTest。
2.5 基础爬虫案例实战
我们已经学习了多进程、requests、正则表达式的基本用法,但还没有完整地实现过一个爬取案例。 这一节,我们就来实现一个完整的网站爬虫,把前面学习的知识点串起来,同时加深对这些知识点的理解。
1. 准备工作
我们需要先做好如下准备工作。
安装好 Python3,最低为 3.6 版本,并能成功运行 Python3 程序。
了解 Python 多进程的基本原理。
了解 Python HTTP 请求库 requests 的基本用法。
了解正则表达式的用法和 Python 中正则表达式库 re 的基本用法。
以上内容在前面的章节中多有讲解,如果尚未准备好,建议先熟悉一下这些内容。
2. 爬取目标
本节我们以一个基本的静态网站作为案例进行爬取,需要爬取的链接为 https://ssrl.scrape.center/,这个网站里面包含一些电影信息,界面如图 2-14 所示。

网站首页展示了一个由多个电影组成的列表,其中每部电影都包含封面、名称、分类、上映时间、评分等内容,同时列表页还支持翻页,单击相应的页码就能进入对应的新列表页。
如果我们点开其中一部电影,会进入该电影的详情页面,例如我们打开第一部电影《霸王别姬》,会得到如图 2-15 所示的页面。

这个页面显示的内容更加丰富,包括剧情简介、导演、演员等信息。
我们本节要完成的目标有:
利用 requests 爬取这个站点每一页的电影列表,顺着列表再爬取每个电影的详情页;
用正则表达式提取每部电影的名称、封面、类别、上映时间、评分、剧情简介等内容;
把以上爬取的内容保存为 JSON 文本文件;
使用多进程实现爬取的加速。
已经做好准备,也明确了目标,那我们现在就开始吧。
3. 爬取列表页
第一步爬取肯定要从列表页入手,我们首先观察一下列表页的结构和翻页规则。在浏览器中访问 https://ssr1.scrape.center/,然后打开浏览器开发者工具,如图2-16所示。
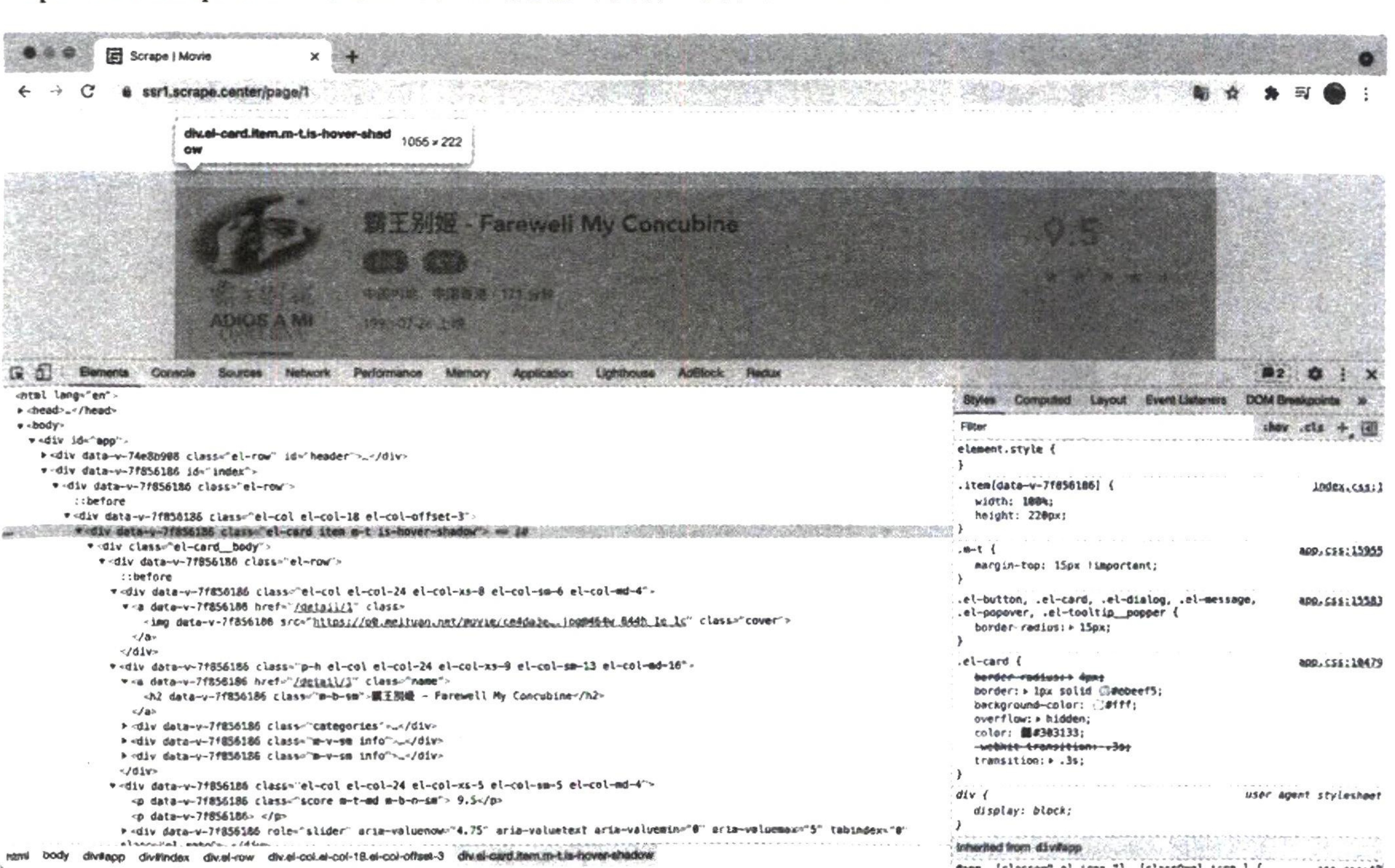
观察每一个电影信息区块对应的 HTML 以及进入到详情页的 URL,可以发现每部电影对应的区块都是一个 div 节点,这些节点的 class 属性中都有 el-card 这个值。 每个列表页有 10 个这样的 div 节点,也就对应着 10 部电影的信息。
接下来再分析一下是怎么从列表页进入详情页的,我们选中第一个电影的名称,看下结果,如图2-17所示。

可以看到这个名称实际上是一个h2节点,其内部的文字就是电影标题。
h2节点的外面包含一个a节点,这个a节点带有href属性,这就是一个超链接,其中href的值为/detail/1,
这是一个相对网站的根 URL https://ssr1.scrape.center/的路径,
加上网站的根 URL 就构成了 https://ssr1.scrape.center/detail/1,也就是这部电影的详情页的URL。
这样我们只需要提取这个 href 属性就能构造出详情页的URL 并接着爬取了。
接下来我们分析翻页的逻辑,拉到页面的最下方,可以看到分页页码,如图2-18所示。

可以观察到这里一共有100条数据,页码最多是10。 我们单击第2页,如图2-19所示。

可以看到网页的 URL 变成了https://ssrl.scrape.center/page/2,相比根 URL多了/page/2这部分内容。 网页的结构还是和原来一模一样,可以像第1页那样处理。
接着我们查看第3页、第4页等内容,可以发现一个规律,这些页面的URL 最后分别为/page/3、/page/4。 所以,/page后面跟的就是列表页的页码,当然第1页也是一样,我们在根 URL 后面加上/page/1也是能访问这页的,只不过网站做了一下处理,默认的页码是1,所以第一次显示的是第1页内容。
好,分析到这里,逻辑基本清晰了。
于是我们要完成列表页的爬取,可以这么实现:
遍历所有页码,构造10页的索引页URL;
从每个索引页,分析提取出每个电影的详情页URL。
那么我们写代码来实现一下吧。 首先,需要先定义一些基础的变量,并引入一些必要的库,写法如下:
import requests
import logging
import re
from urllib.parse import urljoin
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - % (levelname)s: %(message)s')
BASE_URL = 'https://ssr1.scrape.center'
TOTAL_PAGE = 10这里我们引入了 requests 库用来爬取页面、logging库用来输出信息、re库用来实现正则表达式解析、urljoin 模块用来做URL的拼接。
接着我们定义了日志输出级别和输出格式,以及 BASE_URL 为当前站点的根 URL, TOTAL_PAGE 为需要爬取的总页码数量。
完成了这些工作,来实现一个页面爬取的方法吧,实现如下:
def scrape_page(url):
logging.info('scraping %s...', url)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
logging.error('get invalid status code %s while scraping %s',
response.status_code, url)
except requests.RequestException:
logging.error('error occurred while scraping %s', url,
exc_info=True)考虑到不仅要爬取列表页,还要爬取详情页,所以这里我们定义了一个较通用的爬取页面的方法,叫作 scrape_page,它接收一个参数 url,返回页面的 HTML 代码。
上面首先判断状态码是不是 200,如果是,就直接返回页面的 HTML 代码;如果不是,则输出错误日志信息。
另外这里实现了 requests 的异常处理,如果出现了爬取异常,就输出对应的错误日志信息。
我们将 logging 库中的 error 方法里的 exc_info 参数设置为 True,可以打印出 Traceback 错误堆栈信息。
好了,有了 scrape_page 方法之后,我们给这个方法传入一个 url,如果情况正常,它就可以返回页面的 HTML 代码了。
在 scrape_page 方法的基础上,我们来定义列表页的爬取方法吧,实现如下:
def scrape_index(page):
index_url = f'{BASE_URL}/page/{page}'
return scrape_page(index_url)方法名称叫作 scrape_index,这个实现就很简单了,这个方法会接收一个 page 参数,即列表页的页码,我们在方法里面实现列表页的 URL 拼接,然后调用 scrape_page 方法爬取即可,这样就能得到列表页的 HTML 代码了。
获取了 HTML 代码之后,下一步就是解析列表页,并得到每部电影的详情页的 URL,实现如下:
def parse_index(html):
pattern = re.compile('<a.*?href="(.*?)".*?class="name">')
items = re.findall (pattern, html)
if not items:
return []
for item in items:
detail_url = urljoin(BASE_URL, item)
logging.info('get detail url %s', detail_url)
yield detail_url这里我们定义了 parse_index 方法,它接收一个参数 html,即列表页的 HTML 代码。
在 parse_index 方法里,我们首先定义了一个提取标题超链接 href 属性的正则表达式,内容为:
`<a.*?href="(.*?)".*?class="name">`其中我们使用非贪婪通用匹配.*?来匹配任意字符,同时在 href 属性的引号之间使用了分组匹配(.*?)正则表达式,这样我们便能在匹配结果里面获取 href 的属性值了。
正则表达式后面紧跟着 class="name",用来标示这个<a>节点是代表电影名称的节点。
现在有了正则表达式,那么怎么提取列表页所有的 href 值呢?使用 re 库的 findall 方法就可以了,第一个参数传入这个正则表达式构造的 pattern 对象,第二个参数传入 html,这样 findall 方法便会搜索 html 中所有能与该正则表达式相匹配的内容,之后把匹配到的结果返回,并赋值为 items。
如果 items 为空,那么可以直接返回空列表;如果 items 不为空,那么直接遍历处理即可。
遍历 items 得到的 item 就是我们在上文所说的类似 /detail/1 这样的结果。 由于这并不是一个完整的 URL,所以需要借助 urljoin 方法把 BASE_URL 和 href 拼接在一起,获得详情页的完整 URL, 得到的结果就是类似 https://ssr1.scrape.center/detail/1 这样的完整 URL,最后调用 yield 返回即可。
现在我们通过调用 parse_index 方法,往其中传入列表页的 HTML 代码,就可以获得该列表页中所有电影的详情页 URL 了。
接下来我们对上面的方法串联调用一下,实现如下:
def main():
for page in range(1, TOTAL_PAGE + 1):
index_html = scrape_index(page)
detail_urls = parse_index(index_html)
logging.info('detail urls %s', list(detail_urls))
if __name__ == '__main__':
main()这里我们定义了 main 方法,以完成对上面所有方法的调用。 main 方法中首先使用 range 方法遍历了所有页码,得到的 page 就是 1-10;接着把 page 变量传给 scrape_index 方法,得到列表页的 HTML; 把得到的 HTML 赋值为 index_html 变量。 接下来将 index_html 变量传给 parse_index 方法,得到列表页所有电影的详情页 URL,并赋值为 detail_urls, 结果是一个生成器,我们调用 list 方法就可以将其输出。
运行一下上面的代码,结果如下:
2020-03-08 22:39:50,505 - INFO: scraping https://ssr1.scrape.center/page/1...
2020-03-08 22:39:51,489 - INFO: get detail url https://ssr1.scrape.center/detail/1
2020-03-08 22:39:51,950 - INFO: get detail url https://ssr1.scrape.center/detail/2
2020-03-08 22:39:51,950 - INFO: get detail url https://ssr1.scrape.center/detail/3
2020-03-08 22:39:51,950 - INFO: get detail url https://ssr1.scrape.center/detail/4
2020-03-08 22:39:51,950 - INFO: get detail url https://ssr1.scrape.center/detail/5
2020-03-08 22:39:51,950 - INFO: get detail url https://ssr1.scrape.center/detail/6
2020-03-08 22:39:51,950 - INFO: get detail url https://ssr1.scrape.center/detail/7
2020-03-08 22:39:51,950 - INFO: get detail url https://ssr1.scrape.center/detail/8
2020-03-08 22:39:51,950 - INFO: get detail url https://ssr1.scrape.center/detail/9
2020-03-08 22:39:51,950 - INFO: get detail url https://ssr1.scrape.center/detail/10
2020-03-08 22:39:51,951 - INFO: detail urls ['https://ssr1.scrape.center/detail/1', 'https://ssr1.scrape.center/detail/2', 'https://ssr1.scrape.center/detail/3', 'https://ssr1.scrape.center/detail/4', 'https://ssr1.scrape.center/detail/5', 'https://ssr1.scrape.center/detail/6', 'https://ssr1.scrape.center/detail/7', 'https://ssr1.scrape.center/detail/8', 'https://ssr1.scrape.center/detail/9', 'https://ssr1.scrape.center/detail/10']
2020-03-08 22:39:51,951 - INFO: scraping https://ssr1.scrape.center/page/2...
2020-03-08 22:39:52,842 - INFO: get detail url https://ssr1.scrape.center/detail/11
2020-03-08 22:39:52,842 - INFO: get detail url https://ssr1.scrape.center/detail/12
...输出内容比较多,这里只贴了一部分。
可以看到,程序首先爬取了第 1 页列表页,然后得到了对应详情页的每个 URL,接着再爬第 2 页、第 3 页,一直到第 10 页,依次输出了每一页的详情页 URL。 意味着我们成功获取了所有电影的详情页 URL。
4. 爬取详情页
已经可以成功获取所有详情页 URL 了,下一步当然就是解析详情页,并提取我们想要的信息了。
首先观察一下详情页的 HTML 代码,如图 2-20 所示。

经过分析,我们想要提取的内容和对应的节点信息如下。
封面:是一个img节点,其class 属性为cover。
名称:是一个h2节点,其内容是电影名称。
类别:是span 节点,其内容是电影类别。span节点的外侧是 button 节点,再外侧是class 为 categories 的div 节点。
上映时间:是span节点,其内容包含上映时间,外侧是class为info的div 节点。另外提取结果中还多了“上映”二字,我们可以用正则表达式把日期提取出来。
评分:是一个p节点,其内容便是电影评分。p节点的class属性为 score。
剧情简介:是一个p节点,其内容便是剧情简介,其外侧是class为drama的div 节点。
看着有点复杂吧,不用担心,正则表达式在手,我们都可以轻松搞定。 接着实现一下代码吧。 我们已经成功获取了详情页URL,下面当然是定义一个详情页的爬取方法了,实现如下:
def scrape_detail(url):
return scrape_page(url)这里定义了一个 scrape_detail方法,接收一个参数url,并通过调用scrape_page 方法获得网页源代码。 由于我们刚才已经实现了 scrape_page 方法,所以这里不用再写一遍页面爬取的逻辑,直接调用即可,做到了代码复用。 另外有人会说,这个 scrape_detail 方法里面只调用了 scrape_page方法,而没有别的功能,那爬取详情页直接用 scrape_page 方法不就好了,还有必要再单独定义 scrape_detail方法吗?有必要,单独定义一个 scrape_detail方法在逻辑上会显得更清晰,而且以后如果想对 scrape_detail 方法进行改动,例如添加日志输出、增加预处理,都可以在scrape_detail里实现,而不用改动 scrape_page方法,灵活性会更好。 好了,详情页的爬取方法已经实现了,接着就是对详情页的解析了,实现如下:
def parse_detail(html):
cover_pattern = re.compile('class="item.*?<img.*?src="(.*?)".*?class="cover">', re.S)
name_pattern = re.compile('<h2.*?>(.*?)</h2>')
categories_pattern = re.compile('<button.*?category.*?<span>(.*?)</span>.*?</button>', re.S)
published_at_pattern = re.compile('(\d{4}-\d{2}-\d{2})\s?上映')
drama_pattern = re.compile('<div.*?drama.*?>.*?<p.*?>(.*?)</p>', re.S)
score_pattern = re.compile('<p.*?score.*?>(.*?)</p>', re.S)
cover = re.search(cover_pattern, html).group(1).strip() if re.search(cover_pattern, html) else None
name = re.search(name_pattern, html).group(1).strip() if re.search(name_pattern, html) else None
categories = re.findall(categories_pattern, html) if re.findall(categories_pattern, html) else []
published_at = re.search(published_at_pattern, html).group(1) if re.search(published_at_pattern, html) else None
drama = re.search(drama_pattern, html).group(1).strip() if re.search(drama_pattern, html) else None
score = float(re.search(score_pattern, html).group(1).strip()) if re.search(score_pattern, html) else None
return {
'cover': cover,
'name': name,
'categories': categories,
'published_at': published_at,
'drama': drama,
'score': score
}这里我们定义了 parse_detail 方法,用于解析详情页,它接收一个参数为 html,解析其中的内容,并以字典的形式返回结果。
每个字段的解析情况如下所述。
cover:封面。其值是带有 cover 这个 class 的 img 节点的 src 属性的值,所以 src 的内容使用 (.*?) 来表示即可,在 img 节点的前面我们再加上一些用来区分位置的标识符,如 item。由于结果只有一个,因此写好正则表达式后用 search 方法提取即可。
name:名称。其值是 h2 节点的文本值,因此可以直接在 h2 标签的中间使用 (.*?) 表示。因为结果只有一个,所以写好正则表达式后同样用 search 方法提取即可。
categories:类别。我们注意到每个 category 的值都是 button 节点里面 span 节点的值,所以写好表示 button 节点的正则表达式后,直接在其内部 span 标签的中间使用 (.*?) 表示即可。因为结果有多个,所以这里使用 findall 方法提取,结果是一个列表。
published_at:上映时间。由于每个上映时间信息都包含“上映”二字,日期又都是一个规整的格式,所以对于上映时间的提取,我们直接使用标准年月日的正则表达式 (\d{4}-\d{2}-\d{2}) 即可。因为结果只有一个,所以直接使用 search 方法提取即可。
drama:直接提取 class 为 drama 的节点内部的 p 节点的文本即可,同样用 search 方法提取。
score:直接提取 class 为 score 的 p 节点的文本即可,由于提取结果是字符串,因此还需要把它转成浮点数,即 float 类型。
上述字段都提取完毕之后,构造一个字典并返回。
这样,我们就成功完成了详情页的提取和分析。
最后,稍微改写一下 main 方法,增加对 scrape_detail 方法和 parse_detail 方法的调用,改写如下:
def main():
for page in range(1, TOTAL_PAGE + 1):
index_html = scrape_index(page)
detail_urls = parse_index(index_html)for detail_url in detail_urls:
detail_html = scrape_detail(detail_url)
data = parse_detail(detail_html)
logging.info('get detail data %s', data)这里我们首先遍历 detail_urls,获取了每个详情页的URL;然后依次调用了 scrape_detail 和 parse_detail 方法;最后得到了每个详情页的提取结果,赋值为 data 并输出。
运行结果如下:
2020-03-08 23:37:35,936 INFO: scraping https://ssr1.scrape.center/page/1...
2020-03-08 23:37:36,833 INFO: get detail url https://ssr1.scrape.center/detail/1
2020-03-08 23:37:36,833 INFO: scraping https://ssr1.scrape.center/detail/1...
2020-03-08 23:37:39,985 INFO: get detail data {'cover': 'https://po.meituan.net/movie/
ce4da3e03e655b5b88ed31b5cd7896cf62472.jpg@464w_644h_1e_1c', 'name':'霸王别姬 - Farewell My Concubine',
'categories': ['剧情','爱情'], 'published_at': '1993-07-26', 'drama':'影片借一出《霸王别姬》的京戏,
牵扯出三个人之间一段随时代风云变幻的爱恨情仇。段小楼(张丰毅饰)与程蝶衣(张国荣饰)是一对打小一起长大
的师兄弟,两人一个演生,一个饰旦,一向配合天衣无缝,尤其一出《霸王别姬》,更是誉满京城,为此,两人约定
合演一輩子《霸王别姬》。但两人对戏剧与人生关系的理解有本质不同,段小楼深知戏非人生,程蝶衣则是人戏不分。
段小楼在认为该成家立业之时迎娶了名妓菊仙(巩俐饰),致使程蝶衣认定菊仙是可耻的第三者,使段小楼做了叛徒,
自此,三人围绕一出《霸王别姬》生出的爱恨情仇战开始随着时代风云的变迁不断升级,终酿成悲剧。', 'score': 9.5}
2020-03-08 23:37:39,985 INFO: get detail url https://ssr1.scrape.center/detail/2
2020-03-08 23:37:39,985 INFO: scraping https://ssr1.scrape.center/detail/2...
2020-03-08 23:37:41,061 - INFO: get detail data {'cover': 'https://p1.meituan.net/movie/6bea9af4524dfbd
0b668eaa7e187c3df767253.jpg@464w_644h_1e_1c', 'name':'这个杀手不太冷- Léon', 'categories': ['剧情',
'动作','犯罪'], 'published_at': '1994-09-14', 'drama':'里昂(让·雷诺饰)是名孤独的职业杀手,受人雇佣。
一天,邻居家小姑娘马蒂尔德(纳塔丽·波特曼饰)敲开他的房门,要求在他那里暂避杀身之祸。原来邻居家的主人
是警方缉毒组的眼线,只因贪污了一小包毒品而遭恶警(加里·奥德曼饰)杀害全家的惩罚。马蒂尔德得到里昂的
留救,幸免于难,并留在里昂那里。里昂教小女孩使枪,她教里昂法文,两人关系日趋亲密,相处融洽。女孩想着去报仇,
反倒被抓,里昂及时赶到,将女孩救回。混杂着哀怨情仇的正邪之战渐次升级,更大的冲突在所难免………………', 'score': 9.5}
2020-03-08 23:37:41,062 INFO: get detail url https://ssr1.scrape.center/detail/3由于内容较多,这里省略了后续内容。 至此,我们已经成功提取出了每部电影的基本信息,包括封面、名称、类别等。
5. 保存数据
成功提取到详情页信息之后,下一步就要把数据保存起来了。 由于到现在我们还没有学习数据库的存储,所以临时先将数据保存成文本格式,这里我们可以一个条目定义一个JSON文本。
定义一个保存数据的方法如下:
import json
from os import makedirs
from os.path import exists
RESULTS_DIR = 'results'
exists(RESULTS_DIR) or makedirs(RESULTS_DIR)
def save_data(data):
name = data.get('name')
data_path = f'{RESULTS_DIR}/{name}.json'
json.dump(data, open(data_path, 'w', encoding='utf-8'),
ensure_ascii=False, indent=2)这里我们首先定义保存数据的文件夹 RESULTS_DIR,然后判断这个文件夹是否存在,如果不存在则创建一个。
接着,我们定义了保存数据的方法 save_data,其中先是获取数据的 name 字段,即电影名称,
将其当作 JSON 文件的名称;然后构造 JSON 文件的路径,接着用 json 的 dump 方法将数据保存成文本格式。
dump 方法设置有两个参数,一个是 ensure_ascii,值为 False,可以保证中文字符在文件中能以正常的中文文本呈现,
而不是 unicode 字符;另一个是 indent,值为 2,设置了 JSON 数据的结果有两行缩进,让JSON数据的格式显得更加美观。
接下来把 main 方法稍微改写一下就好了,改写如下:
def main():
for page in range(1, TOTAL_PAGE + 1):
index_html = scrape_index(page)
detail_urls = parse_index(index_html)
for detail_url in detail_urls:
detail_html = scrape_detail(detail_url)
data = parse_detail(detail_html)
logging.info('get detail data %s', data)
logging.info('saving data to json file')
save_data(data)
logging.info('data saved successfully')这就是加了对 save_data 方法调用的 main 方法,其中还加了一些日志信息。
重新运行,我们看下输出结果:
2020-03-09 01:10:27,094 - INFO: scraping https://ssr1.scrape.center/page/1...
2020-03-09 01:10:28,019 INFO: get detail url https://ssr1.scrape.center/detail/1
2020-03-09 01:10:28,019 INFO: scraping https://ssr1.scrape.center/detail/1...
2020-03-09 01:10:29,183 INFO: get detail data {'cover': 'https://po.meituan.net/movie/ce4da3e03e655b5b88
ed31b5cd7896cf62472.jpg@464w_644h_1e_1c', 'name': '霸王别姬- Farewell My Concubine', 'categories':
['剧情','爱情'], 'published_at': '1993-07-26', 'drama':'影片借一出《霸王别姬》的京戏,牵扯出三个人
之间一段随时代风云变幻的爱恨情仇。段小楼(张丰毅饰)与程蝶衣(张国荣饰)是一对打小一起长大的师兄弟,
两人一个演生,一个饰旦,一向配合天衣无缝,尤其一出《霸王别姬》,更是誉满京城,为此,两人约定合演一辈子
《霸王别姬》。但两人对戏剧与人生关系的理解有本质不同,段小楼深知戏非人生,程蝶衣则是人戏不分。段小楼在
认为该成家立业之时迎娶了名妓菊仙(巩俐饰),致使程蝶衣认定菊仙是可耻的第三者,使段小楼做了叛徒,自此,
三人围绕一出《霸王别姬》生出的爱恨情仇战开始随着时代风云的变迁不断升级,终酿成悲剧。', 'score': 9.5}
2020-03-09 01:10:29,183 INFO: saving data to json file
2020-03-09 01:10:29,288 INFO: data saved successfully
2020-03-09 01:10:29,288 INFO: get detail url https://ssr1.scrape.center/detail/2
2020-03-09 01:10:29,288 INFO: scraping https://ssr1.scrape.center/detail/2...
2020-03-09 01:10:30,250 INFO: get detail data {'cover': 'https://p1.meituan.net/movie/6bea9af4524dfbd
Ob668eaa7e187c3df767253.jpg@464w_644h_1e_1c', 'name':'这个杀手不太冷- Léon', 'categories': ['剧情',
'动作','犯罪'], 'published_at': '1994-09-14', 'drama':'里昂(让·雷诺饰)是名孤独的职业杀手,受人
雇佣。一天,邻居家小姑娘马蒂尔德(纳塔丽·波特曼饰)敲开他的房门,要求在他那里暂避杀身之祸。原来邻居家
的主人是警方缉毒组的眼线,只因贪污了一小包毒品而遭恶警(加里·奥德曼饰)杀害全家的惩罚。马蒂尔德得到里
昂的留救,幸免于难,并留在里昂那里。里昂教小女孩使枪,她教里昂法文,两人关系日趋亲密,相处融洽。女孩
想着去报仇,反倒被抓,里昂及时赶到,将女孩救回。混杂着哀怨情仇的正邪之战渐次升级,更大的冲突在所难免………………,
'score': 9.5}
2020-03-09 01:10:30,250 INFO: saving data to json file
2020-03-09 01:10:30,253 INFO: data saved successfully通过运行结果可以发现,这里成功输出了将数据存储到JSON文件的信息。
运行完毕之后,我们可以观察下本地的结果,可以看到 results 文件夹下多了100个 JSON文件,每部电影数据都是一个 JSON 文件,文件名就是电影名,如图2-21 所示。

6. 多进程加速
由于整个爬取是单进程的,而且只能逐条爬取,因此速度稍微有点慢,那有没有方法对整个爬取过程进行加速呢?
前面我们讲了多进程的基本原理和使用方法,下面就来实践一下多进程爬取吧。
由于一共有10页详情页,且这10页内容互不干扰,因此我们可以一页开一个进程来爬取。 而且因为这10个列表页页码正好可以提前构造成一个列表,所以我们可以选用多进程里面的进程池 Pool 来实现这个过程。
这里我们需要改写下 main 方法,实现如下:
import multiprocessing
def main(page):
index_html = scrape_index(page)
detail_urls = parse_index(index_html)
for detail_url in detail_urls:
detail_html = scrape_detail(detail_url)
data = parse_detail(detail_html)
logging.info('get detail data %s', data)
logging.info('saving data to json data')
save_data(data)
logging.info('data saved successfully')
if __name__ == '__main__':
pool = multiprocessing.Pool()
pages = range(1, TOTAL_PAGE + 1)
pool.map(main, pages)
pool.close()
pool.join()我们首先给 main 方法添加了一个参数 page,用以表示列表页的页码。
接着声明了一个进程池,并声明 pages 为所有需要遍历的页码,即 1-10。
最后调用 map 方法,其第一个参数就是需要被调用的参数,第二个参数就是 pages,即需要遍历的页码。
这样就会依次遍历 pages 中的内容,把 1-10 这 10 个页码分别传递给 main 方法,并把每次的调用分别变成一个进程,
加入进程池中,进程池会根据当前运行环境来决定运行多少个进程。
例如我的机器的 CPU 有 8 个核,那么进程池的大小就会默认设置为 8,这样会有 8 个进程并行运行。
运行后的输出结果和之前类似,只是可以明显看到,多进程执行之后的爬取速度快了很多。可以清空之前的爬取数据,会发现数据依然可以被正常保存成 JSON 文件。
好了,到现在为止,我们就完成了全站电影数据的爬取,并实现了爬取数据的存储和优化。
7. 总结
本节用到的库有 requests、multiprocessing、re、logging 等,通过这个案例实战,我们把前面学习到的知识都串联了起来,对于其中的一些实现方法,可以好好思考和体会,也希望这个案例能够让你对爬虫的实现有更实际的了解。
本节代码参见:[https://github.com/Python3WebSpider/ScrapeSsrl](https://github.com/Python3WebSpider/ScrapeSsrl)。